

If standing up an AI workspace at your company still takes a week of tickets, you're playing last season's game. AWS just made that feel like opening a Google Doc.
Amazon SageMaker Unified Studio now gives you one-click onboarding and serverless notebooks with a built-in AI agent. No domain provisioning. No instance wrangling. No permission rabbit holes. You click, it just works.
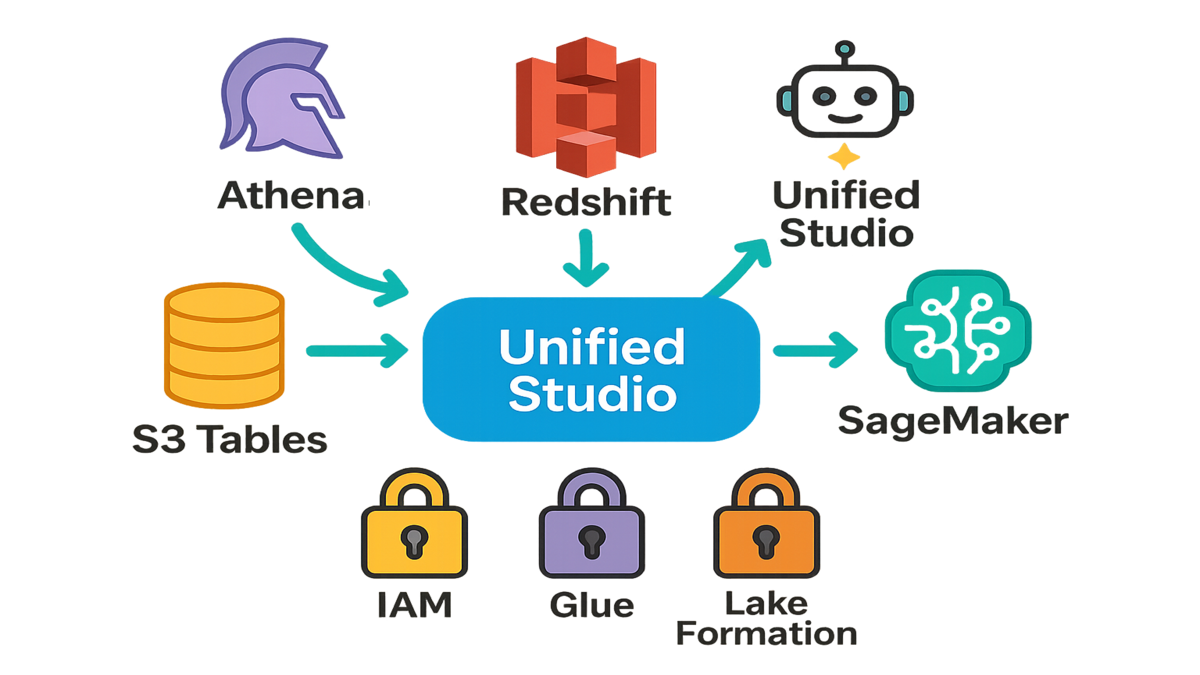
And the kicker: you can launch it straight from the Athena, Redshift, SageMaker, or Amazon S3 Tables consoles. Query data, build models, ship apps—without tool-switching or copy and paste gymnastics. If you've been waiting for a clean on-ramp to analytics + AI on AWS, this is it.
If your current path looks like this, it's rough. File a ticket. Wait two days for a domain. Spin up a notebook instance. Ask security for exceptions. Then chase down an IAM role. Unified Studio collapses that into one decision: which role do you want to use? That's it. You're in and already pointing at the data you're allowed to touch.
The vibe is simple: move from "project setup" to "running code" in minutes, not days. For teams hungry to prototype real use cases—forecasting, churn, cost analytics—this isn't just nice-to-have. It's a productivity unlock with guardrails that keep security teams smiling.
TLDR
- One-click onboarding inherits existing AWS data permissions—no manual setup.
- Launch Unified Studio from Athena, Redshift, S3 Tables, or SageMaker.
- Serverless notebooks unify SQL, Python, and natural language prompts.
- Built-in AI agent writes code, converts prompts, automates grunt work.
- Governance stays intact via IAM, Glue Data Catalog, Lake Formation.
- Collaborate and ship faster—all in one managed, serverless environment.
What Changed
The big unlock
SageMaker Unified Studio now onboards you with one click. Your project inherits data permissions from AWS Glue Data Catalog, AWS Lake Formation, and Amazon S3—so you can start working right away. No manual domain provisioning. No compute setup. Just select or create the IAM role you want, and you're in.
This means you skip the old "make me a workspace" dance. The notebook comes online with the context your role already has. If your org uses Lake Formation for fine-grained table and column access, those rules follow you into the notebook. You get speed and the same policy you rely on in Athena.
Permissions without migraines
Because Studio piggybacks off permissions you already manage in Glue, Lake Formation, and IAM, it respects the governance model you've already built. That means the same access controls you use for queries in Athena or tables in S3 carry over to notebooks, pipelines, and ML workflows—minimizing policy drift and shadow access.
Bonus: centralizing permissions in one place cuts down on the classic "this notebook works for me but not for you" debugging. If the role can read a dataset in Athena today, it can read it in Studio. If permissions change tomorrow, Studio honors that change—no secret local exceptions.
From Zero To Queries
You're a data engineer with tables already cataloged in Glue, locked down via Lake Formation. In Unified Studio, you click "Get started," pick your IAM role, and land in a serverless notebook. No provisioning dialog. You immediately run SQL against Athena, pivot to Python to explore, and spin up a model—all in the same place. The move from "I have data" to "I have insights" stops being a project plan and becomes a session.
Within 30 minutes, you've validated joins across two business tables, profiled a few columns for data drift, and drafted a baseline feature set. Because the notebook inherits the right access, there's no detour into role assumptions or inline credentials. You stay in flow.
Why It Matters
- Fewer hops: less context switching means fewer errors and faster iteration.
- Lower ops overhead: serverless notebooks mean compute is managed for you.
- Real governance: inherited permissions mean you demo fast without breaking rules.
- Cleaner audits: policy changes in IAM and Lake Formation reflect instantly in Studio activity.
- Less rework: shared patterns and roles reduce "works on my machine" surprises.
Pro tip: define a few "golden roles" for common personas (analyst, DS, DE). When new teammates join, they choose the role that matches their job and start shipping.
Serverless Notebooks With AI Agent
SQL Python And Prompts
Serverless notebooks in SageMaker Unified Studio are a single canvas where you mix SQL queries, Python code, and natural language prompts. You analyze data, test logic, and build ML models without juggling tools or environments.
The feel is familiar—cells, outputs, plots—but without the boilerplate of standing up kernels or picking instance sizes up front. Need to query Athena? Run a cell. Want to explore features with Pandas? Same notebook. Ready to test a classifier or a regressor? Import the SDKs and go. It's one narrative that stitches data-to-model without leaving the page.
What The AI Agent Does
The built-in AI agent sits in the notebook to:
- Generate code from natural language ("Create a join across these tables, then compute week-over-week growth").
- Suggest boilerplate and utilities (Athena queries, Pandas transformations, visualization starters).
- Translate between SQL and Python, cut repetitive tasks, and reduce debugging time. You get notebooks with a built-in AI agent—no plugins or extra services to wire up.
Think of it like the teammate who reads your prompt, checks the data shape you're working with, and drafts the first pass. You still review and edit, but you're not staring at a blank cell. Ask it to refactor, add comments, or test for edge cases. It'll scaffold the boring parts so you stay in the problem.
Prompt Patterns That Work
- Give it schema: "Table: salesfact (orderid, customerid, amount, ts), customersdim (customerid, state, signup_dt)."
- Ask for idempotent code: "Make it safe to re-run cells without duplicating tables."
- Specify outputs: "Return a Matplotlib chart and a summary table rounded to 2 decimals."
- Request guardrails: "Validate nulls and outliers; fail gracefully with a helpful message."
Prompt To Pipeline
You ask, "Load last 90 days of Redshift sales, calculate LTV by cohort, and chart top 10." The agent drafts SQL, scaffolds Python for feature creation, then proposes a quick model baseline. You tweak, run, and ship. It's one-click onboarding of existing datasets to a notebook that behaves like a teammate.
In practice, that might look like this. The agent writes a window function to compute customer cohorts, uses a join to bring in marketing channels, and suggests a quick regression or classification benchmark. You accept the core cells, add business definitions (e.g., active customer), and push a versioned artifact to your team space. The path from idea to "something people can react to" is absurdly short.
Why It Matters
- Speed: less boilerplate, more outcomes.
- Consistency: standardized patterns across teams.
- Accessibility: analysts can move up the stack; engineers move faster.
- Learning loop: the agent's drafts become living examples for newer teammates.
- Fewer handoffs: one person can take a problem further before calling in reinforcements.
Cost tip: serverless means you're not paying for idle instances. Close the notebook, and you're not burning compute. Open it when you need it, scale when you must, without picking instance sizes in advance.
Skip The Tool Switch Tax
Four Front Doors One Studio
You can launch SageMaker Unified Studio directly from:
- Amazon Athena
- Amazon Redshift
- Amazon S3 Tables
- Amazon SageMaker That's a fast path from data services to ML workflows inside one environment.
This matters because the best time to experiment is the second you see something interesting in your data. If you're in a console and you have to copy credentials, open a new tool, and re-point at the same tables, you lose momentum. With Studio, you keep context and move forward.
Why Entry Points Matter
Most AI delays aren't model math—they're context friction: tab sprawl, permission mismatches, and brittle copy and paste code. Direct launch collapses distance between "I see the data" and "I'm experimenting with it."
You also reduce the configuration divergence problem. The role that let you preview a table is the same role evaluating that data in the notebook. No hidden env vars, no conflicting SDK versions. You reduce both technical and cognitive overhead.
Analyst To Builder
You're in the Athena console viewing a query result set. Click to open in Unified Studio. The notebook already knows your permissions and data context. You outline a prompt, the agent drafts the SQL-to-Python pipeline, and you export a chart and save a model artifact. No juggling credentials, SDK versions, or drivers.
Next, you post the notebook link in your team channel. A data scientist opens it, swaps the baseline model for a more robust one, adds cross-validation, and logs metrics. An engineer reviews, wraps the workflow with a job definition, and schedules it. Same file, same environment—different depths of contribution.
The Compounding Effect
- Faster handoffs: analysts, scientists, and engineers share the same workspace.
- Less glue code: you don't re-create context between systems.
- Fewer errors: permission alignment reduces brittle workarounds. If you've ever stitched Redshift queries to a separate notebook service and then wrangled IAM for S3 access, this will feel like skipping an entire chapter.
Add in one more benefit: centralized lineage. When your data lives in S3, is cataloged in Glue, and is governed by Lake Formation, your notebook activity sits on top of the same stack. That makes audits and reviews much less painful.
Governed Speed
Inherited Access Consistent Governance
Unified Studio respects the roles and permissions you manage with IAM, Glue Data Catalog, Lake Formation, and S3—so your lakehouse governance comes along for the ride. Teams can explore data, share analytics, and manage model artifacts without inventing a parallel permission universe.
If you leverage Lake Formation for row-level or column-level constraints, those policies determine what's visible in the notebook. Catalog entries in Glue define the canonical view of your datasets, with schema and ownership. IAM scopes who can run what. It's the same operating model security and data teams already know.
DevOps Aligned ML
Because notebooks are serverless and studio-managed, you avoid VM drift and ad hoc setup. That unlocks cleaner CI/CD for ML, easier code reviews, and simpler reproducibility. The result: collaboration that actually scales. And with SageMaker-native catalogs and registries in the broader ecosystem, you can keep lineage and artifacts traceable without duct tape.
Practically, this means fewer environment recreation headaches. You can pin dependencies in cells, export code to jobs, and reuse templates across pods. When the platform handles compute, you spend your time on experiment quality, not kernel plumbing.
Shared Project Without Chaos
Your team launches a shared project in Unified Studio. Data scientists ship baseline notebooks; data engineers productionize the same code path; analysts create visual outputs. Access is scoped via IAM and Lake Formation, artifacts live in AWS-native stores, and everything is auditable. It's the collaboration model enterprises wanted—without slowing to a crawl.
A lead can review a single workspace for dataset sources, transformation code, charts, and model metrics. Security can confirm that access followed policy. Stakeholders get a link and a demo. The work is centralized, reviewable, and repeatable.
Why It Matters
- Security teams are happier: centralized policy, fewer exceptions.
- Leaders see outcomes: notebooks to apps within existing guardrails.
- You move faster with less risk: the real enterprise unlock.
- Continuity during turnover: projects live in the platform, not personal laptops.
- Easier audits: one trail across data access, code, and artifacts.
Governance tip: tag projects and resources. Consistent tags help cost tracking, ownership, and cleanup policies. If every notebook and artifact carries a team, use case, and environment tag, life gets easier.
What To Do Next
Start Small Scale Fast
Pilot Unified Studio on a single high-value use case, like churn prediction. Or forecasting and cost analytics. The goal isn't a science project; it's a production path.
Pick a use case with clear success criteria and a decision-maker waiting on it. The tighter the loop, data to insight to action, the faster you prove value. Resist the urge to boil the ocean—your first win is the template for the next three.
Suggested Rollout Path
- Identify 1–2 data domains with clean Glue cataloging and Lake Formation permissions.
- Bring one cross-functional pod: analyst + data scientist + engineer.
- Use serverless notebooks only—no manual compute provisioning.
- Lean on the AI agent for code scaffolds, SQL translation, and refactors.
- Convert the winning notebook to a repeatable template for the next team.
Want a jumpstart on query automation and SQL-to-Python workflows? Explore Requery.
Add These Rhythms
- 2x weekly 30-minute working sessions to unblock and standardize snippets.
- A Friday demo: one chart, one metric, one decision.
- A running glossary: document table semantics in the first notebook cell.
- A shared repo of "good cells" (joins, validations, feature encoders) to reuse.
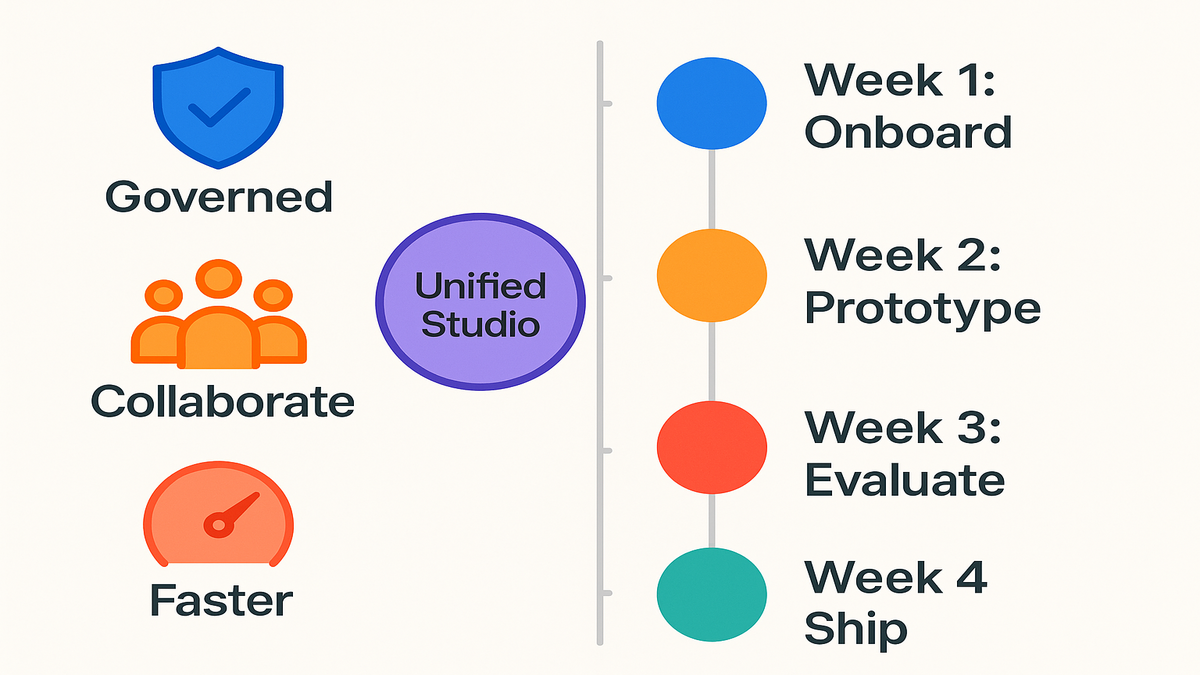
30 Day Win
Week 1: onboard via one click, connect to Athena, document data context. Week 2: prototype model and dashboards in the same notebook. Week 3: add evaluation, tighten prompts, and standardize code snippets. Week 4: hand off to engineering for productionization—still inside Studio.
What makes this work: a single owner, a DRI, explicit handoff criteria, and a clear decision the output will influence. Your momentum compels adoption more than any slide deck.
Quick Pulse Check
- You can launch Unified Studio from Athena, Redshift, S3 Tables, or SageMaker.
- One-click onboarding inherits IAM, Glue, and Lake Formation permissions.
- Serverless notebooks unify SQL, Python, and prompts; the AI agent accelerates code.
- Collaboration and governance stay intact—no parallel permission universe.
- The fastest path is a focused pilot that becomes your template.
Track Your Scoreboard
- Time-to-first-query, minutes from onboarding to first successful data pull.
- Time-to-first-model, hours from baseline dataset to a scored result.
- Number of reusable cells or templates created per week.
- Percentage of projects launched without new IAM policies.
- Stakeholder cycle time, from insight to decision.
FAQ
Provision Domain Or Instances
No. Unified Studio's serverless notebooks remove manual domain and compute provisioning for starting projects. You choose or create an IAM role, and Studio handles the underlying resources so you can get straight to work.
How Permissions Carry Over
Unified Studio inherits your existing access controls. If a user or role can query a table in Athena based on Glue and Lake Formation permissions, that access is honored in Studio notebooks. You keep a single source of truth for governance.
Mix SQL And Python
Yes. Serverless notebooks support SQL queries alongside Python, and you can use natural language prompts with the built-in AI agent to generate code, translate between SQL and Python, and automate repetitive steps.
AI Agent And Data
Your data stays in your AWS account under your configured IAM, Glue, Lake Formation, and S3 policies. Review the data usage documentation for the specific AI capabilities you enable and your organization's governance requirements.
Pricing Overview
You pay for the underlying AWS services you use. For SageMaker features, see the SageMaker pricing page. Queries against Athena, Redshift, or S3 follow their respective pricing. Always check the current pricing pages before scaling usage.
Launch From Redshift And S3
Yes. You can open Unified Studio from the Redshift, Athena, SageMaker, and Amazon S3 Tables consoles, which streamlines movement from data exploration to ML workflows.
Difference From Classic Studio
Historically, teams often created domains and managed notebook instances or kernel gateways before doing any work. Unified Studio focuses on serverless notebooks with one-click onboarding and direct launch from data services, cutting setup time and aligning permissions you already maintain.
Call Bedrock Models
Yes. You can use the AWS SDKs from your notebook to call services like Amazon Bedrock, subject to your IAM permissions and service quotas. Many teams pair analytics in Athena or Redshift with generative AI via Bedrock in the same workflow.
Control Costs
Use tags, budget alerts, and keep notebooks lean. Close idle sessions, sample data before full runs, and parameterize expensive queries. Monitor service-specific costs across SageMaker, Athena, Redshift, and S3 so you see the full picture.
Networking And Security
Follow your organization's standard AWS practices: encryption at rest and in transit, scoped IAM roles, and governed access via Lake Formation. If you use private networking patterns, align with your cloud team's guidance and the relevant AWS documentation.
Ship Your First Project
1) In the SageMaker console, click Get started in Unified Studio. 2) Select or create an IAM role with required data permissions. 3) Open a serverless notebook; verify access to Glue-cataloged data. 4) Run a quick Athena or Redshift query to pull a sample dataset. 5) Use a natural language prompt to generate starter analysis code. 6) Explore in Python, iterate, and chart results. 7) Save artifacts and share with your team—all inside Studio.
Two Day One Guardrails
- Create a "sandbox" database or schema for scratch tables and temp outputs.
- Store reusable cells in a shared snippet notebook so the next project starts faster.
The shortest path to a working demo starts with one focused dataset and a clear business question.
Here's the punchline: AWS collapsed setup time to near zero, glued data and AI into one flow, and gave you an AI agent to cut busywork. That combo moves you from "we should test this idea" to "we shipped a result" on a single screen. If your team lives in Athena, Redshift, S3 Tables, or SageMaker already, Unified Studio is the on-ramp to deliver outcomes faster—with your governance intact. Your next move is simple: pick one use case, onboard with one click, and let the serverless plus agent combo do the unglamorous work so you can focus on impact.
"In 2025, the fastest AI teams won't write more code—they'll remove more steps."
Looking for real-world examples of analytics-to-ML rollouts? Browse our Case Studies.
References
- Amazon SageMaker (service overview)
- Amazon SageMaker Studio (documentation)
- AWS Glue (service overview)
- AWS Glue Data Catalog (documentation)
- AWS Lake Formation (service overview)
- AWS Identity and Access Management (IAM)
- Amazon Athena (service overview)
- Amazon Redshift (service overview)
- Amazon Bedrock (service overview)
- Amazon SageMaker pricing
- AWS CloudTrail (service overview)
- AWS Budgets (service overview)