


You already have plenty of data across tools and teams. What you don’t have is real findability across assets, not yet.
Teams burn hours asking which table is correct, or who owns this feature today. Meanwhile, your unstructured stuff in S3—PDFs, images, transcripts—just sits there like a junk drawer.
Here’s the unlock: Amazon SageMaker Catalog layers business context on your technical metadata automatically. It writes descriptions, suggests use cases, applies glossary terms, enforces what “PII” means at your company, and makes everything searchable across assets.
You stop guessing, and you start shipping real work without the drag.
And the kicker? It works where you already live, inside Amazon SageMaker Unified Studio and via the SageMaker Catalog API. So you can generate column-level descriptions with Bedrock-powered LLMs, apply metadata forms, restrict sensitive classifications, and see lineage from raw S3 object to model.
Governance that actually speeds you up.
This is how you turn “we’re not sure” into “let’s go.”
TLDR
- Generate business descriptions and column-level metadata with LLMs (via Amazon Bedrock) in a few clicks.
- Enforce glossary and metadata forms so teams use the same language—and the right labels.
- Discover structured, semi-structured, and unstructured S3 assets in one unified catalog.
- Govern with restricted classification terms, approvals, and usage monitoring.
- Reuse ML features via feature-level metadata; track lineage for audit and trust.
- Works in Amazon SageMaker Unified Studio and programmatically via the SageMaker Catalog API.
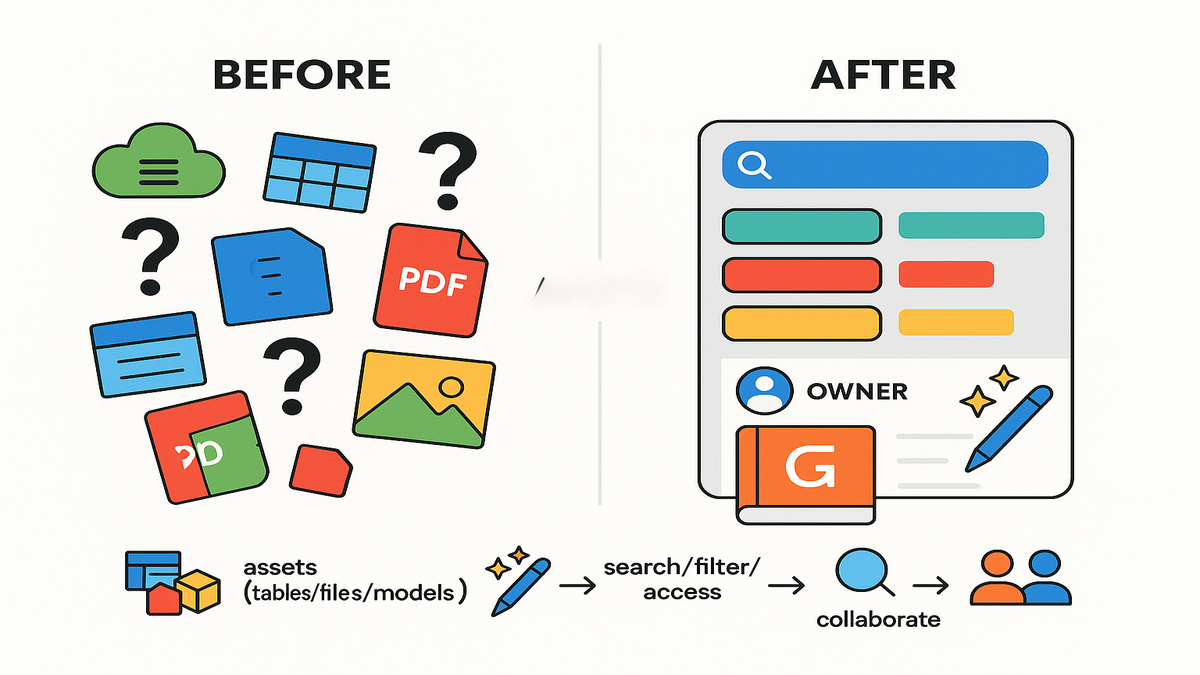
Why Your Metadata Is Failing
Tech Metadata Without Business Meaning
Your warehouse knows a table is named salestxnagg_v3, versioned and all. Your data lake knows exactly where the file lives in Amazon S3. None of that tells a business analyst if it’s quarter-closed, or if returns are netted.
It also doesn’t say if it’s safe for a marketing model, which is risky. That’s the gap: technical metadata exists, but the business context doesn’t show up.
SageMaker Catalog fills it by attaching business metadata like descriptions, glossary terms, owners, sensitivity, and operational attributes. People can actually discover and trust assets, without digging.
And it does this across both structured data and the messy unstructured stuff in general-purpose S3 buckets. No more separate catalogs, and no more context lost in Slack threads.
Think about every “quick question” thread your team sent this week. Is this table current? Who approves access? Can we use this for EU users? Those aren’t schema issues—they’re context questions.
The Catalog answers them up front by showing the key facts next to the asset. The result is less scavenger hunting, and fewer retries because you picked the wrong source.
Add ownership and sensitivity right on the asset, and your collaboration gets safer. Analysts can find datasets ready for BI, while data scientists can find raw-but-governed assets for modeling.
No one steps on each other’s toes, which is nice.
SageMaker Catalog in plain English
- You register assets (tables, files, models, dashboards).
- Catalog enriches them with business metadata, both automatic and manual.
- You search by business terms, filter by governed attributes, request access, and collaborate.
If your teams run workflows in SageMaker Studio, this becomes your default source of truth. That unified layer cuts onboarding time and reduces duplicate work across squads.
Think of it like “Google for your data plus rules to use it safely,” built into your ML stack. Here’s why that matters in practice: a new hire can search “churn propensity features” on day one and get answers.
They immediately see vetted feature groups, owners, usage notes, and sensitivity flags. They don’t guess which version is good or DM five people for a link.
That is the difference between a fast org and a thrashy one.
Pro tip: model your business glossary like you model a product. Start with the 30–50 terms your teams argue about the most.
Lock those down first, then expand. With enforced definitions, “active customer,” “lead,” and “consented user” stop being fuzzy and become filters.
Generative AI Writes Descriptions
What It Automates And Why
SageMaker Catalog uses LLMs powered by Amazon Bedrock to write business descriptions and suggest use cases. It can also produce column-level summaries for structured assets.
You get consistent, policy-aligned text that explains what the dataset is. It covers how columns should be interpreted and where the asset is best applied.
Here’s the practical win: docs that took hours now take minutes, honestly. You can generate suggestions, review them, tweak, and publish right in Unified Studio.
This isn’t a black box; you stay in the loop and approve everything. You can enforce your glossary so the language matches your company standards.
Quality also jumps right away. When the LLM reads the schema and drafts with your glossary in mind, it catches mismatches early.
For example, a column named email_sha1 gets flagged as likely sensitive. It suggests a proper classification, so your review is focused, not a blank page job.
To get the most from it, set simple acceptance rules before publishing. For example: every dataset needs purpose, freshness or SLAs, and flagged columns for PII.
That way the AI suggestions stay consistent across teams, every single time.
Quality control checklist you can adopt today:
- Does the description describe purpose, not just structure?
- Are sensitive fields labeled using approved glossary terms?
- Is lineage visible or linked (source system, transformation notes)?
- Are usage notes clear (best for segmentation, not for billing)?
- Is an owner assigned and reachable?
How it fits your workflow
- In Unified Studio, open an asset, click generate business description, review, publish. Done.
- For complex assets like Apache Iceberg tables backed by Amazon S3, the model reads schema and context.
- Programmatically register assets and attach generated metadata using the SageMaker API Reference. Search for relevant endpoints as the sagemaker catalog api evolves.
Example you can run with your team: take a marketing analytics table with 200 columns. Generate column-level descriptions and suggested analytical use cases in a single pass.
Apply restricted classifications to the columns containing emails or device IDs, then publish. You just created a high-signal, governed “amazon sagemaker catalog metadata discoverability organizations example” that reduces onboarding friction immediately.
Another quick win: a bundle of PDF research studies stored in S3. Register the folder as a dataset, add a project tag and retention policy, and generate a summary.
Highlight what each document covers for fast scanning by the team. Now a data scientist searching for "trial protocol inclusion criteria" lands on the right documents.
They also see the right cautions, which helps prevent mistakes.
One Catalog To Break Silos
Structured Unstructured One Place
Historically, you kept separate catalogs for warehouse tables and unstructured data. That guarantees context rot and broken trails across the org.
SageMaker Catalog brings them together cleanly. You can publish S3 datasets like PDFs, images, and text dumps with business metadata fields.
Add project, study, protocol, retention policy—whatever your team needs for clarity. Now both analysts and data scientists can search governed assets with confidence.
Search for "clinical protocol PDFs" or "customer consent recordings" and actually find them. The glossary terms and access constraints are baked right in.
No more “which bucket was that again?” detective work across people and folders. This also unlocks end-to-end projects that used to stall for weeks.
Picture a fraud model that needs both transaction tables and call-center transcripts. In one search, you find vetted features, the approved transcripts dataset, and full lineage.
One workspace, one set of rules, less chaos, more output.
Discovery Access Collaboration Workflow
- Search and filter by business terms, owners, sensitivity, and custom attributes.
- Request access and track approvals without leaving your workspace.
- Collaborate in projects using SageMaker Studio projects and notebooks.
Put simply: Catalog turns your S3 general-purpose buckets into a governed, discoverable layer. It plugs straight into your ML and analytics pipeline.
If you’re evaluating a “sagemaker unified catalog” approach for BI and ML, this is the keystone. A small, high-leverage move helps a ton.
Standardize a short set of custom attributes across your top assets. Think data freshness, legal basis for processing, and retention window.
When those fields are consistent, your search filters become a superpower. For example, “show datasets with 24-hour freshness that support EU marketing consent.”
Halfway Check What You Unlocked
- You can auto-generate business and column-level descriptions with Bedrock-backed LLMs.
- You can unify discovery across structured, semi-structured, and unstructured S3 assets.
- You can search by business terms, enforce glossary standards, and restrict sensitive labels.
- You can collaborate directly in Unified Studio projects with approvals and access gating.
- You’re setting up reuse for ML features and lineage for audit-ready traceability.
Here’s a quick diagnostic: if “where’s the right table?” shows up less in Slack, you’re on track. If approvals still pile up in email, wire them into Studio projects and IAM roles.
That closes the loop and reduces manual follow-ups every single week.
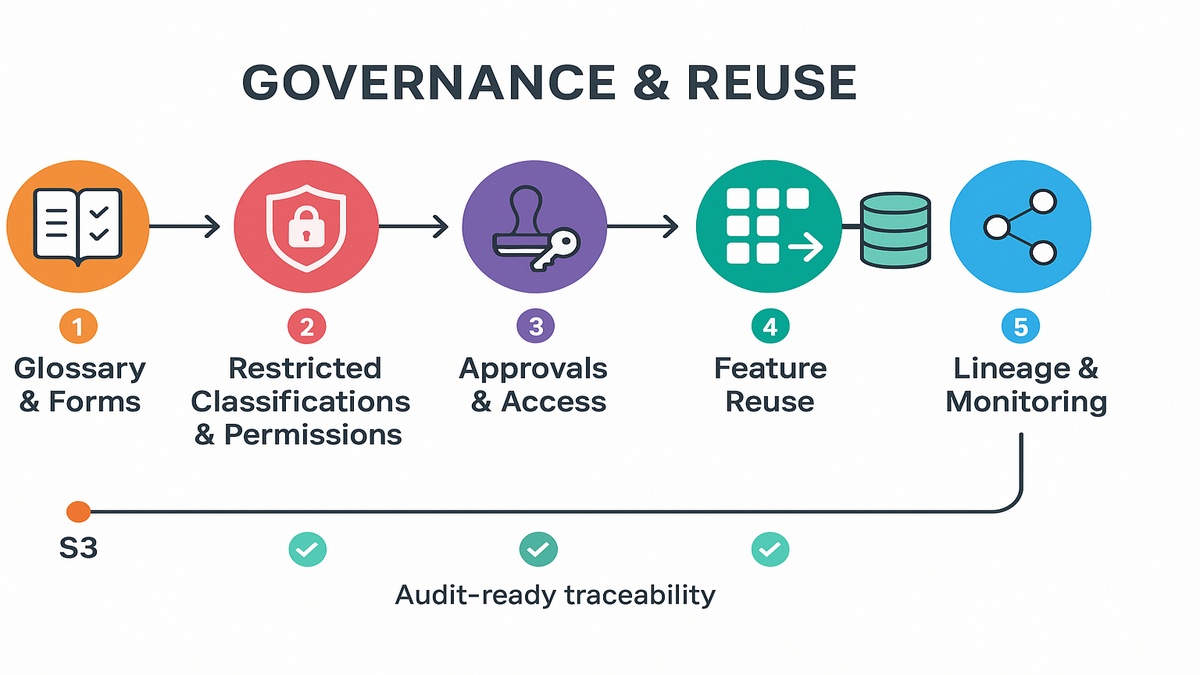
Governance That Doesnt Slow You
Enforced Glossaries And Metadata Forms
This is where rigor meets speed in a practical way. Admins can publish metadata forms with required fields to keep order.
Think business owner, classification, retention, and other basics you always chase. You can attach forms to assets, including column-level metadata forms where needed.
Pair that with enforced glossary requirements so “PII,” “PHI,” and “Confidential” mean the same thing. They always mean exactly what they should mean across the company.
When someone onboards a new dataset, Catalog checks the form first. No owner or no classification? It doesn’t pass, and that’s on purpose.
This reduces mystery data and creates consistent signals your search can rely on. It also makes reviews faster since fields are predictable and clean.
Best practice playbook:
- Make “Owner” and “Intended Use” required on every asset.
- Use picklists, not free text, for sensitivity and lifecycle stage.
- Keep forms short (10 fields max) so teams actually fill them out.
- Add column-level forms only to high-value tables to avoid noise.
- Review forms quarterly as your policies evolve.
Guardrails And Permissions You Trust
Use metadata enforcement rules and restricted classification terms to control labels. Only designated stewards can mark something as "Restricted" or "Export Controlled."
Combine that with approval workflows and IAM policies for full governance. For identity and role setups, see AWS Identity and Access Management.
Also check the SageMaker Studio administrator workflows for onboarding steps. See the Studio Admin docs for the full process and details.
If you’re building an “amazon sagemaker unified studio administrator guide,” use this backbone. Glossaries, forms, access policies, and audit logs work together well.
It’s governance as code, enforced by the platform, not tribal knowledge. Security hygiene tips you’ll thank yourself for later:
- Separate steward permissions from creator permissions.
- Require approvals for any sensitivity downgrade.
- Log access decisions for audits and post-mortems.
- Tag assets with legal basis, where applicable, to simplify reviews.
Make ML Reusable
Searchable Features That Scale Models
SageMaker Catalog lets you add searchable metadata at the feature level. This works directly in SageMaker Feature Store today.
Tag features by sensitivity, source system, transformation, last modified, and intended use. Modelers can search, evaluate, and reuse vetted features instead of recreating them.
This reduces training time and improves consistency across your portfolio of models. It also helps you retire duplicate or deprecated features with less drama.
Ownership and usage become visible, which nudges better behavior at scale. The practical move is to promote a shortlist of “golden” features.
They’re tested, described, and approved for reuse across teams. Add use notes like “ideal for weekly churn models; refreshed nightly.”
That turns a feature store into a force multiplier, not a dumping ground. Less guessing, more reuse, better outcomes week after week.
Lineage For Audit And Debugging
Catalog automatically captures lineage like origin, transformations, model usage, and governance state. Tie this to SageMaker ML Lineage Tracking for full traceability.
You can answer the questions auditors and your future self ask. Where did this dataset come from, and which transformations introduced that null spike?
Which model used this feature last quarter, and did it pass approvals? When you can trace from raw S3 object to trained model, confidence goes up.
That includes approvals and glossary decisions across the pipeline. It’s the foundation for responsible AI at scale and a key part of the “amazon sagemaker unified studio workload capabilities” story.
Debugging bonus: lineage shortens incident response by a lot. If a dashboard spikes, you can trace the upstream change and who approved it.
You also see which model or feature group propagated the change downstream. You fix it in hours, not weeks, and move on.
Rollout Plan You Can Run
- Pick 1–2 high-impact domains (marketing, risk, clinical) and nominate data stewards.
- Define your glossary and metadata forms (owner, sensitivity, retention, SLA). Include column-level forms for key tables.
- Register 10–20 priority assets across S3 and warehouses; generate descriptions with Bedrock; review and publish.
- Enforce glossary requirements and restricted classification terms for sensitive labels.
- Tag feature groups in Feature Store with business metadata; promote top reusable features.
- Wire approvals and access via IAM and Studio projects; document your “sagemaker catalog documentation” internally.
- Monitor search and adoption; iterate forms and rules; expand to the next domain.
If you want a simple scorecard for your first month:
- Time to find the “right” dataset drops by 50% for your pilot team.
- 90% of pilot assets have owners, sensitivity, and intended use filled.
- Feature reuse is visible, with at least 3 models using the same approved features.
- Approvals and access get handled inside Studio, not via email anymore.
After month one, expand to the next domain and repeat the playbook. The key is cadence: keep weekly steward reviews and a lightweight backlog of glossary updates.
FAQs
What Is Amazon SageMaker Catalog
SageMaker Catalog is a data and AI governance service inside Amazon SageMaker. It attaches business context like descriptions, glossary terms, classifications, and owners to your technical metadata.
It unifies discovery and governance for structured, semi-structured, and unstructured assets. Teams can find, trust, and use data faster inside SageMaker Studio.
How Is This Different
AWS Glue Data Catalog manages technical metadata for data lakes and ETL. Amazon DataZone supports org-wide data discovery and governance across services.
SageMaker Catalog focuses on business metadata and ML workflows inside SageMaker Unified Studio. It spans data, models, and features for ML-centric context and collaboration.
They’re complementary: Glue for technical schemas, DataZone for enterprise sharing, and SageMaker Catalog for ML teams. Together, they cover your stack.
Use Catalog API To Automate
Yes. You can programmatically register assets and attach metadata via the SageMaker API Reference. As the sagemaker catalog api surface expands, check docs for the latest endpoints.
Support Iceberg And S3 Objects
Yes. You can register complex structured assets like Iceberg tables stored in Amazon S3. You can also publish unstructured and semi-structured S3 datasets with business metadata.
That gives you one place to discover everything, from curated tables to PDFs and images. One catalog, fewer blind spots, better results.
Set Up Access And Approvals
Use Catalog’s approval workflows alongside IAM roles and policies. Restrict who can apply sensitive classification terms, and require metadata forms for onboarding.
For Studio user and project setup, see the Studio admin onboarding docs. Also review Studio projects for collaboration.
Available In My AWS Region
Check the AWS Regional Services table to confirm coverage and updates.
You can also consult the SageMaker release notes and sagemaker catalog documentation for region-specific announcements. Regions do roll out on their own timelines.
Handle Personally Identifiable Information
Use your glossary to define PII precisely for your organization, then enforce it. Limit who can apply or change those labels, and require approvals for any access.
Combine with IAM roles and logging to keep a full audit trail of access. You’ll know who accessed what and why, which matters a lot.
Can Nontechnical Stakeholders Use Catalog
Yes. The whole point of business metadata is to make assets understandable. With human-readable descriptions, owners, and intended-use notes, anyone can use it.
Product managers, marketers, and risk partners can discover and request access. They won’t need to read schemas or code to make sense of assets.
If Teams Register Similar Assets
Use ownership and “intended use” to differentiate them and reduce confusion. Then consolidate or deprecate duplicates based on your standards.
The Catalog’s search and lineage make overlap obvious for stewards. Add a deprecation date to older assets and point users to the preferred source.
How Do We Measure Success
Track time-to-discovery for new projects and completeness of metadata forms. Also watch feature reuse rates across models and approval turnaround time.
If those trend in the right direction, your metadata is doing its job. Less scavenger hunting, more building, fewer confused threads.
You want less hunting and more building, that’s the goal here. SageMaker Catalog ties business meaning to your technical reality, clean and simple.
Start with one domain, enforce the glossary, and generate column-level context where it matters. Your search results get smarter, approvals get faster, and features get reusable.
And your auditors get much happier, which helps everyone sleep.
There’s a pattern here: teams that ship useful AI at scale treat metadata as product. It’s owned, enforced, and evolved over time until it just works.
This is your moment to make metadata a real advantage for your company. For marketing teams using Amazon Marketing Cloud, a quick note to help.
Tools like AMC Cloud and Requery can operationalize queries and audience workflows on trusted datasets. Use them on top of assets you catalog in SageMaker.
If documentation feels expensive, try confusion. SageMaker Catalog makes the former cheaper so you avoid the latter entirely.
References
- Amazon SageMaker Studio Overview: Amazon SageMaker Studio Overview
- Amazon Bedrock — What is Bedrock?: Amazon Bedrock — What is Bedrock?
- Amazon S3 User Guide: Amazon S3 User Guide
- Amazon SageMaker Feature Store: Amazon SageMaker Feature Store
- Amazon SageMaker ML Lineage Tracking: Amazon SageMaker ML Lineage Tracking
- AWS Glue Data Catalog: AWS Glue Data Catalog
- Amazon DataZone — What is DataZone?: Amazon DataZone — What is DataZone?
- AWS IAM — Introduction: AWS IAM — Introduction
- SageMaker Studio — Admin Onboarding: SageMaker Studio — Admin Onboarding
- Amazon SageMaker API Reference: Amazon SageMaker API Reference
