

You want AI that actually ships, not another week of messy config. This week’s aws bedrock release notes help you do exactly that.
AWS shipped updates that cut friction where it hurts badly. Smarter Knowledge Bases in Amazon Bedrock, performance and adoption boosts for Amazon Nova. And tighter security for serverless endpoints using CloudFront OAC on Lambda function URLs. Translation: less glue code, fewer brittle edges, cleaner path from prototype to production.
If you’ve waited for an aws bedrock drop with speed and control, this is it. You get domain-aware AI without running your own RAG stack. Plus much lower latency inference at true cloud scale today. And a default-deny posture for your serverless APIs, without breaking your front end.
Think practical upgrades you can ship this week, for real. A support copilot that finally cites your docs, and a product finder that answers fast under load. And Lambda URLs that don’t get hammered by random bots. Less duct tape, more shipping, and fewer scary midnight pages.
Here’s the plain-English breakdown of this release, and how to roll it out. What changed, why it matters, and how to ship with minimal drama. Expect quick wins, gotchas to avoid, and a 30-day plan for small teams. No buzzword bingo, just the path from demo to done.
TL;DR
- Bedrock Knowledge Bases get smoother for domain-specific AI apps, with no DIY infrastructure.
- Amazon Nova pushes lower-latency, large-scale inference, plus easier adoption across AWS services.
- CloudFront OAC now plays nicer with Lambda function URLs for secure, fast serverless.
- This aws bedrock blog-style breakdown shows what changed, why it matters, and how to ship.
- Curious about DeepSeek in Amazon Bedrock or amazon nova multimodal embeddings? Not in this drop.
Bedrock Knowledge Bases
What changed
Amazon Bedrock updated Knowledge Bases to make domain-specific AI apps much easier. You can use foundation models from top providers and enrich them with private data. No managing vector databases, chunking pipelines, or custom retrieval logic anymore. In plain English: fewer moving parts, faster RAG.
In practice, you point Bedrock at trusted sources like PDFs, wikis, or a clean S3 bucket. It handles ingestion and embeddings under the hood, then your app calls one consistent API. No scrambling to maintain a retrieval service or fix a parser when formats change. This cuts the annoying “data plumbing tax” that kills so many AI prototypes.
Why you care
RAG gives you reliable, context-aware answers from LLMs, without slow fine-tuning runs. With Knowledge Bases, you point Bedrock at sources, let it handle ingestion and retrieval, then wire your app. You keep data where it belongs, add reasoning where it counts, and avoid wild hallucinations.
Also, Bedrock’s model flexibility means you aren’t locked into a single FM. Start with a budget model while you test prompts and data, then scale quality later. Same interface, far less refactor risk when needs change. And by default, your content isn’t used to train underlying FMs, which calms compliance folks.
First hand example
Say you’re shipping a customer support copilot. You’ve got PDFs of policy docs, a Confluence graveyard, and a product FAQ that changes weekly. With Knowledge Bases, you:
- Connect your document store
- Let Bedrock index and embed
- Ask the model to cite sources in answers
- Expose it behind your existing help widget
Result: relevant, grounded answers without building a bespoke RAG backend. And because it’s Bedrock, you can swap models as your needs evolve.
To make this sing, spend two hours on hygiene and cleanup. Convert scanned PDFs to text, remove superseded docs, and add simple metadata tags. Use version, product, and region so retrieval stays sharp and stable. In prompts, ask for citations and confidence to reduce hallucination worry during demos.
Helpful links: Browse the Bedrock docs for Knowledge Bases and the model catalog. See supported providers and capabilities before you lock choices.
- Knowledge Bases overview (docs)
- Model catalog and providers
Pro tips for Knowledge Bases
- Start small: index one product line or one policy set first.
- Chunk smart: keep short, self-contained sections with clear headings and labels.
- Keep a change log: re-ingest the delta when docs update, not the world.
- Prompt for evidence: “Cite top 2 sources with page or section” as default.
- Evaluate weekly: sample 20 answers, score grounding, prune bad docs, repeat.
Nova gets faster
What changed
Amazon Nova updates focus on performance and adoption across AWS services. Optimized architecture for low-latency, large-scale generative and foundation model inference. The net effect is faster responses, better throughput, and fewer integration hurdles.
In practical terms, expect lower tail latency during spikes and smoother autoscaling behavior. You also get tighter glue with building blocks you already use today. For multimodal or real-time assistants, those small wins stack into a smoother product.
Why you care
Latency is product surface area, and users feel it right away. Every 100ms matters for search, chat, or real-time assistants in production. Nova aims for consistent low-latency inference across heavy loads and traffic spikes. And it plugs into AWS services, so you write less glue and ship more.
There’s also cost control through smarter throughput and better features. Add streaming responses for snappier UX and limit max tokens per route. Cache stable outputs, like common tool calls, at the edge for savings. Your app feels fast and stays affordable under real traffic.
First hand example
You’re launching a multimodal product finder for your main storefront. Users upload a photo, type a question, and get recommendations. Your stack needs to:
- Run fast image-to-text and text-to-text inference
- Orchestrate calls with your catalog search
- Scale cheaply without jitter
With Nova’s integration-first approach, you wire inference and data access natively. Orchestration gets easier using AWS services you already trust and monitor. Note: if you’re scanning aws bedrock new features for “amazon nova multimodal embeddings,” not in this update. This drop emphasized performance and integration, not a new embeddings API.
Practical tuning ideas:
- Stream responses for chat flows to reduce perceived latency for users.
- Batch background jobs, like content summaries, during low-traffic windows.
- Cap max tokens and temperature per route to control speed and style.
- Add a fallback: if the primary model is overloaded, route cheaper for basics.
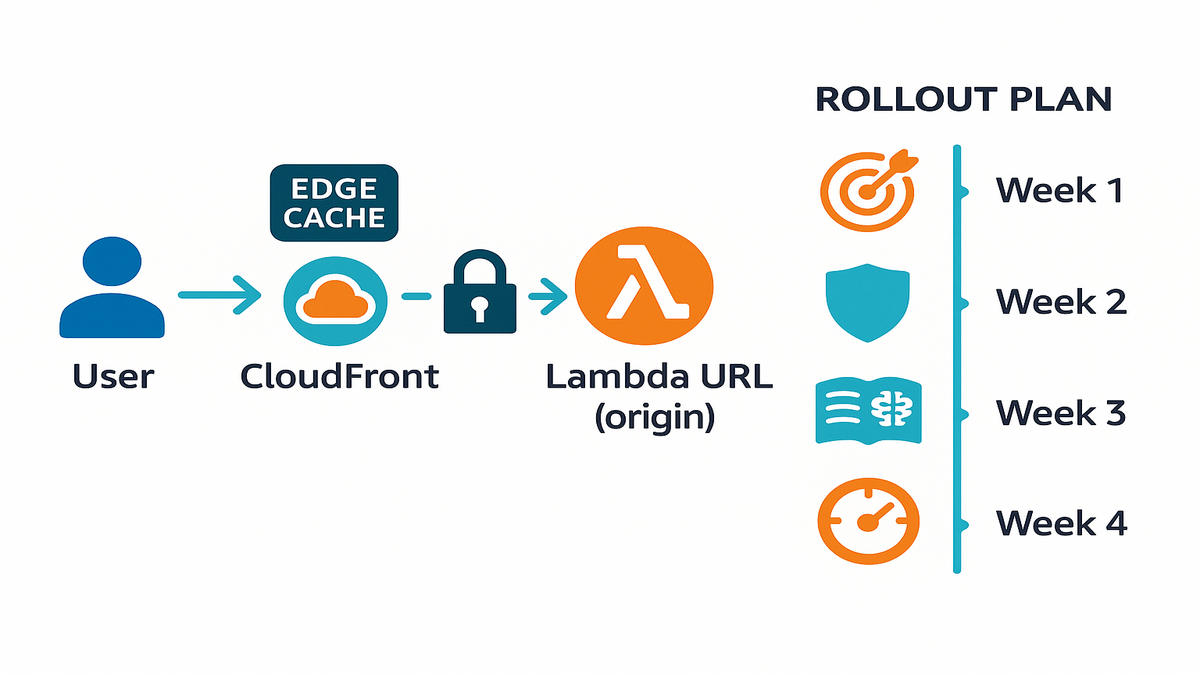
CloudFront OAC for Lambda URLs
What changed
AWS improved support for CloudFront Origin Access Control with Lambda function URLs. You can run your HTTPS Lambda endpoints behind CloudFront and lock the origin. Only CloudFront can call the origin for a clean, default-deny setup.
This pattern gives you signed requests from CloudFront to your origin by default. Origin visibility is off to the public internet for stronger security controls. You get one edge layer for caching, WAF, and DDoS protections too. Cleaner logs, fewer surprises, and happier on-call engineers.
Why you care
Function URLs are great for prototypes and simple APIs, but open endpoints attract abuse. With OAC, you restrict origin access and enforce headers and signatures. Then you layer caching, WAF, and DDoS protections at the edge for safety. Keep the origin dark, latency low, and logs centralized in one place.
You also get consistent routing and powerful edge features without API Gateway. Device or geo headers work fine at the edge for many early needs. If you need API Gateway later, you can switch without breaking your front end.
First hand example
You’ve got a marketing mini-app on a Lambda function URL today. Dynamic personalization, basically zero infrastructure, and simple deploys for the team. It’s getting scraped, and your costs spike hard overnight. The fix:
- Put CloudFront in front
- Configure OAC so only CloudFront reaches the function URL
- Add AWS WAF rules and cache-friendly responses
Now you serve the app from the edge while blocking direct origin hits. Spiky traffic gets tamed without re-platforming or changing your front end.
Rollout checklist for OAC + Lambda URLs:
- Create and attach an OAC to the CloudFront origin for the function URL.
- Restrict the function URL to accept only signed CloudFront requests.
- Add AWS WAF managed rules for bots and rate limits, then tune.
- Set cache policies and vary only on needed headers or query params.
- Turn on CloudFront logs and sample early for misrouted or odd traffic.
From demo to production
Week 1
- Identify your top two workflows, like helpdesk copilot or ops assistant.
- Map data sources for a Bedrock Knowledge Base setup right away.
- Pick a primary FM and a fallback, which switch easily in Bedrock.
Add a simple success metric for each workflow before you start. Reduce time-to-first-answer by 50% or deflect 25% of repetitive tickets. Or cut manual data lookups by a clear, measurable amount this month. Document the current baseline, or you can’t prove the upgrade worked.
Week 2 secure the edges
- Front all function URLs with CloudFront and OAC for safety.
- Add rate limits and bot protections in WAF for stability.
- Centralize logs and tracing so alerts make sense fast.
This is your defense week, so lock origins by default right away. Test with signed edge requests, and add deny-list rules for scrapers. Set a sane rate limit per IP or session to prevent abuse. Pipe logs to a single place so anomalies are easy to spot.
Week 3 harden retrieval
- Index clean, versioned docs in Knowledge Bases for stability.
- Add grounding and citations in prompts for trust and clarity.
- Build red-team tests for prompt injection and jailbreak attempts.
Treat your RAG like a search system with real ownership and versioning. Freeze content windows, delete stale files, and label everything clearly. Add a test suite with tricky prompts that probe boundaries carefully. If it fails, improve instructions and guardrails before you ship.
Week 4 measure tune ship
- Track latency, token usage, helpfulness, and deflection rates weekly.
- Cache sensible responses at the edge to cut cost and tail times.
- Roll out to 10% of users, iterate hard, then scale confidence.
Small rollouts expose weirdness safely and save your weekend on-call hours. Watch tail latency and error spikes, not just averages in dashboards. Trim tokens, add caching headers, or move non-urgent jobs to batch. After two iterations, go to 50% and watch the same metrics again.
First-hand example: teams cut time-to-answer from minutes to seconds with grounding. They used Knowledge Bases and cached common results at CloudFront locations. Meanwhile OAC kept origins dark and abuse out to protect budgets.
Fast rewind
- Bedrock Knowledge Bases reduce RAG plumbing so you can focus on UX.
- Nova’s performance and integration boosts mean lower inference latency at scale.
- CloudFront OAC on Lambda URLs gives you edge speed and origin-level security.
- This aws bedrock announcement prioritizes real-world ship-it upgrades, not buzzwords.
- Want a deeper dive? Check the aws bedrock blog and docs linked below.
Bottom line: fewer moving parts, faster answers, and safer edges everywhere. That combo gets stakeholder buy-in quickly, and helps you keep it.
FAQs
What changed in Knowledge Bases
AWS updated Knowledge Bases to simplify domain-specific apps on Bedrock for teams. You get streamlined retrieval on private data and simpler model integration. Practically speaking, fewer custom pipelines and quicker RAG deployments, with less moving pieces.
DeepSeek in Amazon Bedrock
Not in this update, at least based on what AWS announced here. If you’re tracking “deepseek in amazon bedrock,” check the model catalog. Watch What’s New posts for additions and provider changes in the near future.
Amazon Nova multimodal embeddings
The roundup highlights performance and adoption improvements for Nova overall. Low-latency, large-scale inference and tighter AWS integrations for teams. If you want “amazon nova multimodal embeddings,” not in this drop specifically.
CloudFront OAC with Lambda URLs
OAC restricts origin access so only CloudFront can call your Lambda function URL. You get edge performance and signed or origin-verified requests for safety. It also makes WAF and caching easier to layer without extra services.
Bedrock vs own RAG
Bedrock Knowledge Bases remove a ton of infra work across indexing and retrieval. You also keep model flexibility and avoid lock-in through one interface. DIY may offer deep tuning, but adds big ops burden and slower value.
Swap models in Bedrock
Yes, that’s a core strength and why teams like it right now. Start with one FM for cost and latency goals, then switch later. You avoid rewriting core plumbing thanks to a consistent API surface.
Metrics in production
Track latency for p50 and p90, plus the error rate every week. Also track token usage per route and a helpfulness score from users. For RAG, add grounding rate so answers include valid citations.
Control costs without killing quality
Use streaming for chat, cap tokens per endpoint, and cache stable outputs. Batch non-urgent tasks during night windows to avoid peak costs. Start smaller for easy queries, escalate only when needed for quality.
Data privacy with Bedrock
Keep sensitive docs inside a Knowledge Base you control with tags. Mark PII-heavy content and use least-privilege access on sources. Bedrock is designed so inputs and outputs aren’t used to train FMs by default.
What breaks in RAG setups
Stale or conflicting docs break retrieval, and users get wrong answers quickly. People ingest everything “just in case,” then outdated content gets retrieved. Fix with version tags, a content freeze window, and aggressive deletions.
Need API Gateway with Lambda
Not necessarily, especially for simple apps with light needs and usage. CloudFront plus OAC and WAF is already strong and flexible. If you need request validation or quotas, add API Gateway later.
Test CloudFront OAC safely
Spin up a staging distribution and a separate function URL for tests. Lock the origin and run load tests against CloudFront only here. Try direct origin hits, which should be denied with clear errors.
Launch this week checklist
- Inventory endpoints; front Lambda URLs with CloudFront and OAC immediately.
- Stand up a Bedrock Knowledge Base on a single, clean data source.
- Enable grounding and citations in prompts for trust and traceability.
- Add WAF bot rules and rate limits at the edge for safety.
- Cache stable responses, like marketing and FAQs, to save cost.
- Instrument latency, errors, token usage, and answer quality scores.
- Add fallbacks: model swap plus static copy for outages and spikes.
- Run a small canary rollout and gather feedback within 72 hours.
- Document the playbook, then scale to the next workflow right after.
You don’t need a platform rewrite, just stack smart, ship, and iterate. In a noisy week for AI headlines, this update feels refreshingly practical. You get simpler RAG with Knowledge Bases, faster inference with Nova, and edge-first security. If you do one thing today, put CloudFront and OAC before your Lambda URLs. Then stand up a Bedrock Knowledge Base for your highest-ROI use case now.
Want to apply this playbook to retail media? Explore AMC Cloud and browse our Case Studies for real-world wins.
References
- Amazon Bedrock — Service overview
- Knowledge bases for Amazon Bedrock — Documentation
- Amazon Bedrock model providers and models
- AWS News Blog — Knowledge Bases for Amazon Bedrock
- Using Lambda function URLs — Documentation
- CloudFront Origin Access Control (OAC) overview
- Amazon CloudFront — Product page
- AWS WAF — What is AWS WAF?
- AWS Shield — DDoS protection overview
- Amazon Bedrock — Data privacy and security
- Think with Google — Milliseconds Make Millions (site speed impact)