

You’ve been duct-taping search across PDFs, screenshots, videos, and call audio. It works, until it doesn’t. One query hits text, another hits images. The video archive might as well be a black box. Users ask normal questions. Your stack answers like it learned English yesterday.
Here’s the unlock. A single embedding model that understands text, documents, images, video, and audio. It maps them into one vector space. That’s Amazon Nova Multimodal Embeddings in Amazon Bedrock. One model. One space. Cross-modal search at industry-leading cost.
If multimodal RAG is your next roadmap checkbox, this changes the physics. Take a voice memo, a product clip, a slide deck with charts, and a long FAQ. You can make all of it retrievable, and consistent. Less plumbing. Fewer edge cases. More, wow, that actually worked.
The kicker: you don’t touch infra. Bedrock handles provisioning, endpoints, and scaling. You focus on ingestion, indexing, and prompts. With 8K-token context and 30-second media segments, you’re set. Use smart chunking for longer files. You can tune for speed, accuracy, and storage.
TLDR
- One unified model: map text, docs, images, video, and audio into one vector space for cross-modal search.
- Built for RAG: power agentic retrieval with high recall and simpler pipelines.
- Flexible I/O: up to 8K tokens, 30s video/audio segments; segment bigger files.
- Right-fit costs: pick embedding dimensions to balance accuracy versus storage and latency.
- Operated in Bedrock: synchronous for real-time; async for high-volume or batch.
- Use cases: e-commerce visual and textual search, media archive discovery, compliance docs, and more.
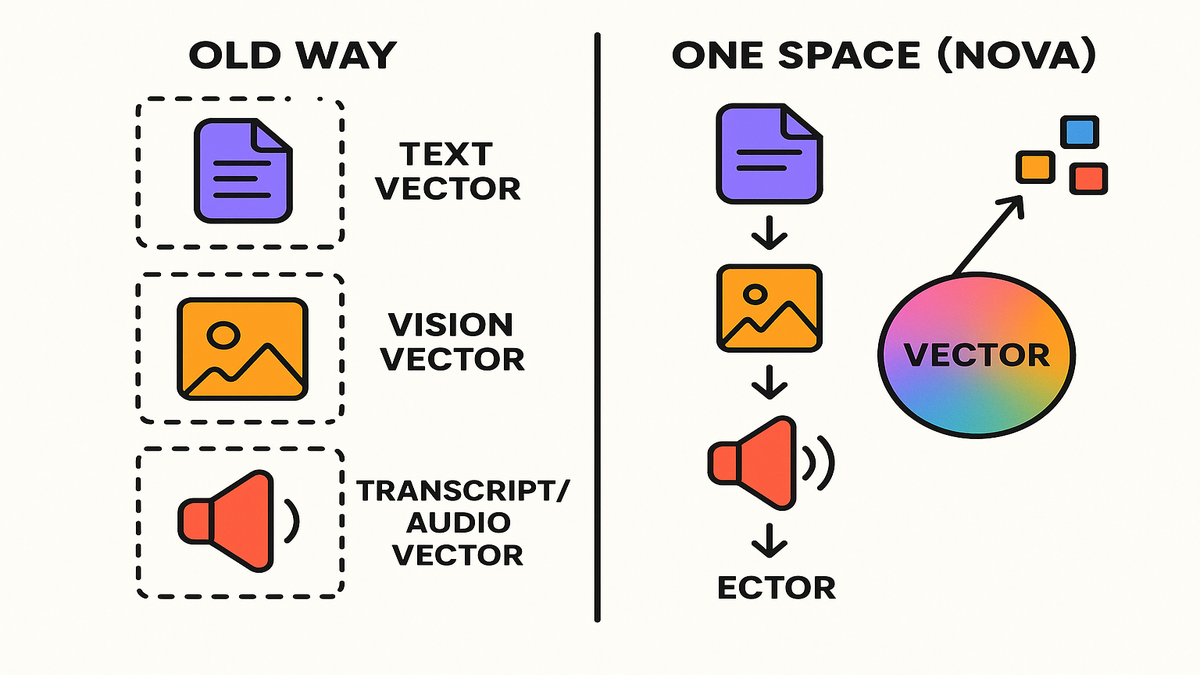
One embedding space changes search
The old way is broken
You probably stitched separate models: a text embedder for docs, a vision model for images. Then something bespoke for audio or video transcripts. That splits your index and complicates ranking. It makes “What’s the clip where the engineer says ‘latency dropped’ while the graph spikes?” nearly impossible.
Nova flips that. As Amazon describes it, it’s “the industry’s first embedding model that supports text, documents, images, video, and audio through a single unified model.” It enables cross-modal retrieval with leading accuracy and cost efficiency. Translation: fewer models, fewer heuristics, better recall.
Cross modal retrieval that works
- One query, many modalities: Ask in natural language. Retrieve a chart image, a relevant video moment, and a paragraph in a PDF. Do it all via nearest-neighbor search in one vector space.
- Mixed content is native: Documents with interleaved text and images just work. Videos with visuals, audio, and captions too. Nova understands those relationships.
- Cleaner ranking: Stop hacking per-modality scores. Rank by one consistent similarity metric instead.
A common result: higher user trust. When search returns the chart, the timestamp, and the sentence that explains it, users believe your system gets it. Wire that into RAG and your model cites stronger evidence. That usually reduces hallucinations and speeds task completion.
Behind the scenes, this works through a shared representation across formats. Think of a multilingual friend who speaks content, not English versus pixels or audio waves. If your query mentions “the chart that spikes after Q2,” the space places that phrase near the exact image region. It also sits near the paragraph explaining the spike. You’re not translating between separate systems. You’re asking one brain to recall one memory.
If you’ve tried cross-modal models like CLIP, the intuition will feel familiar. Align text and visuals so similar concepts cluster. The difference is Nova’s scope. Not just images and captions, but documents, audio, and video moments in one space. That unlocks “find the moment,” not just “find the file.”
Move from simple search to real workflows. Think triaging customer tickets or auditing marketing claims. The reliability from consistent retrieval keeps projects alive past the demo. Teams stop babysitting edge cases, and start building features.
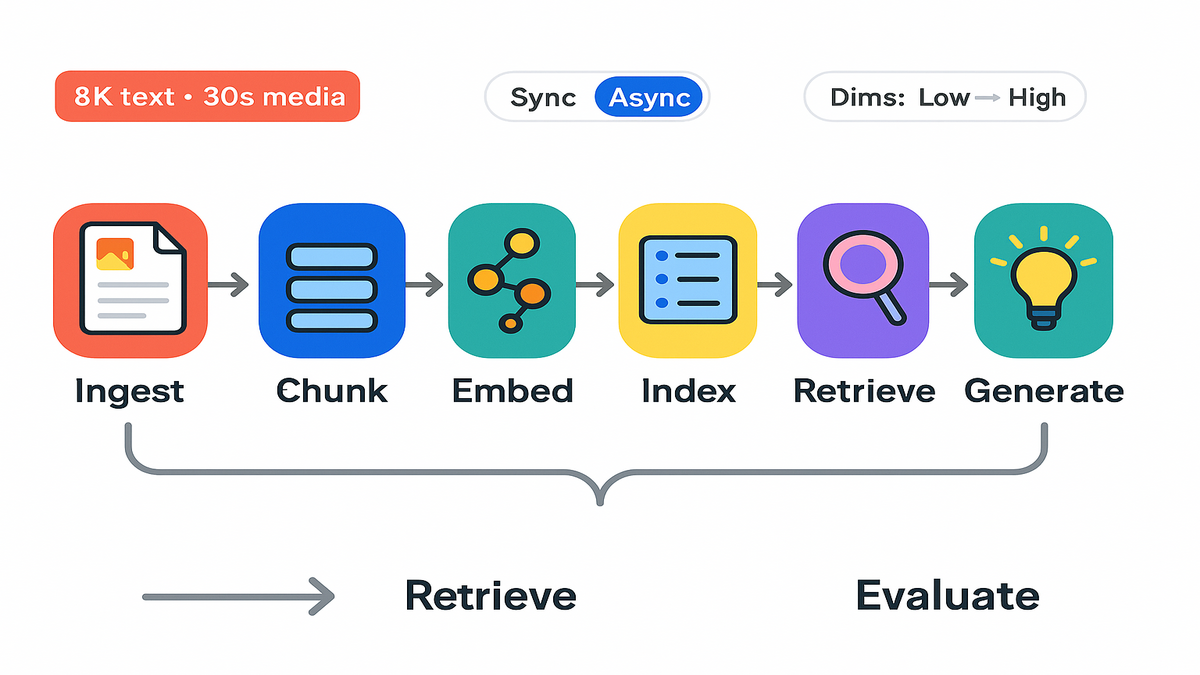
Nova Multimodal Embeddings inside Bedrock
Inputs limits and segmentation
Nova accepts text and documents up to 8K tokens. It handles video and audio segments up to 30 seconds. Larger assets? Segment them. For video, chunk by scene or slide transitions. For audio, chunk by silence or speaker turns. For long PDFs, chunk by headings or logical sections. For example, per chart with its caption. You then embed each chunk. Retrieval reassembles the answer.
“As a single, unified model that supports text, documents, images, video, and audio,” Nova maps them into a unified embedding space. That breaks data silos without you maintaining modality-specific pipelines.
A few practical hints for clean segmentation:
- For PDFs with mixed text and images, keep charts with the paragraph that interprets them. That pairing boosts relevance because meaning often lives in the caption.
- Use gentle overlap for text, around 10–15% of tokens. Avoid chopping key sentences in half. Each chunk should be independently useful.
- Align video chunks to natural boundaries like scene cuts, slide changes, or speaker turns. That keeps a chunk coherent, better for retrieval and playback.
- Normalize media first. Standardize frame rates and audio sample rates. This avoids oddities from mixed encodings.
APIs and workloads
In Amazon Bedrock, you choose:
- Synchronous API for near real-time use, like chat assistants, live search bars, or agent loops.
- Asynchronous API for “nova batch inference” workflows. Think overnight indexing, bulk ingestion, or media library backfills.
Because Bedrock is fully managed, you skip instance sizing and endpoints. You also skip networking glue. You focus on payloads and retrieval logic. Doing an internal “amazon nova multimodal understanding workshop”? This simplicity helps teams ship a proof-of-concept in hours, not weeks.
Operationally, treat synchronous calls like a hot path. Set clear timeouts. Use small chunk sizes for on-the-fly embeds. Cache aggressively to cut repeat work. For async, design for throughput. Batch payloads and parallelize across collections. Track progress so you can resume if a job fails midway. Build idempotency into ingestion. You don’t want duplicate vectors when a job retries.
A clean workflow looks like this. A streaming sync path embeds ad hoc user inputs, like queries and uploads. A steady async pipeline keeps your corpus fresh, like new docs, product media, and edited transcripts. Both feed the same vector store.
Accuracy vs cost your call
Nova offers multiple embedding dimensionalities. Higher dimensions can improve retrieval fidelity. But they produce larger vectors, more storage, and slightly higher latency. Lower dimensions cut costs and can still be strong for many workloads. Pilot both. Measure nDCG and recall@K on a labeled set. Choose what moves your metrics at the best price per query.
Expert tip: normalize vectors and test cosine versus dot product in your vector database. Ranking can shift meaningfully with the right metric.
Napkin math to keep you honest:
- Vector size ≈ dimension × 4 bytes for float32. So 512-d ≈ 2 KB, and 1024-d ≈ 4 KB per vector.
- 10 million chunks at 1024-d is about 40 GB of raw vector data. That’s before index overhead. HNSW or IVF indexes add overhead, so plan headroom.
- Latency scales with both index type and hardware. HNSW gives strong recall with predictable latency. IVF can cut memory footprint with a training step. Benchmark on your corpus.
If your search quality is already good enough at a lower dimension, take the win. Spending 2× on storage to chase a 1–2% recall bump may not move the business.
Designing multimodal RAG that performs
Indexing strategy that doesnt crumble
- Separate but searchable: keep a single index, but tag chunks with metadata. Include modality, source, timestamp, page, and section. This powers faceted filters and layout-aware ranking.
- Field-aware rerank: retrieve top-K by vector similarity. Then rerank using a lightweight model or rules using modality and metadata. Example: prioritize a chart image when the query mentions trend or spike.
“Asynchronous API for efficient processing of larger files” lets you pipeline ingestion. Detect, extract, chunk, embed, and index. For PDFs, capture images and nearby text together. For videos, align visuals, ASR text, and optional captions per 20–30 second chunk.
Build a minimal, stable schema:
- Core fields: id, modality, sourceuri, createdat, and updated_at.
- Context fields: page or slide, timestamp_start and end, speaker, language, and entities.
- Governance fields: sensitivity like PII or finance, access policy, and retention date.
This lets you filter stale or restricted chunks at query time. It keeps answers relevant and compliant.
Chunking video and audio
- Use VAD, or silence detection, to define audio chunks.
- For product demos, align to scene or feature boundaries. Users search by feature names.
- Carry context metadata like speaker, section, and slide timecode. It boosts precision and grounds RAG citations.
Also consider confidence weighting. If your transcript includes ASR confidence scores, store them. At rerank time, slightly downweight segments with poor ASR confidence. Users notice when quotes are crisp and accurate.
When in doubt, sample your chunks. Manually label 50–100 random segments. If a human can’t tell what the chunk is about fast, your chunking is too coarse or messy.
Retrieval that feeds your LLM
- Hybrid search: combine vector with sparse BM25 on captions or transcripts. Great for rare terms and numeric symbols.
- Query rewriting: expand queries with synonyms and modality hints. For example, “find image of login screen,” or “clip where CFO mentions margin.”
- Evidence packing: when sending to the LLM, include multiple modalities. Add the snippet text, the chart image reference, and the video timestamp. Answer quality jumps when the model sees diverse, relevant evidence.
“As Amazon Bedrock is fully managed,” your LLM and retrieval can share one platform. That cuts latency and ops. Need on-the-fly embeddings during a chat? The synchronous API handles it. The rest lives in batch pipelines.
Add a thin relevance guardrail. If top results fall below a similarity threshold, ask a clarifying question. It’s better to ask “Do you mean the 2022 or 2023 report?” than to fake confidence.
Architecture blueprint from content
- Ingestion: watch folders or buckets for new files. Extract text with OCR for images and screenshots. Pull captions for video. Normalize media formats.
- Segmentation: apply rules by modality. Use headings for docs and scenes or speaker turns for video or audio. Keep charts with captions.
- Embedding: call Nova via Bedrock. Store vectors plus rich metadata. Use async for bulk adds. Use sync for ad hoc uploads.
- Indexing: build or update your ANN index like HNSW or IVF. Maintain a sparse index on text fields for hybrid search.
- Retrieval: at query time, run vector and BM25. Merge, then rerank using modality-aware rules.
- Generation: feed the top evidence into your LLM. Include direct citations like page numbers, timestamps, and image IDs.
- Feedback loop: capture clicks, copy events, and thumbs up or down. Use this to refine chunking, rerank rules, and dimension choices.
This blueprint is simple on purpose. Plug in your favorite vector DB like OpenSearch, pgvector, or a managed service. The flow stays the same.
Evaluation and guardrails that scale
- Build a gold set: 100–500 query and answer pairs across all modalities. Don’t skip edge cases like numbers, acronyms, or brand names.
- Metrics that matter: track recall@K and MRR. Also track nDCG to see ordering. Watch latency p95 and cost per query alongside quality.
- Regression tests: when you tweak chunk size or dimension, re-run the full suite. If correctness dips, roll back.
- Human-in-the-loop: sample 1–2% of sessions for review. Label good enough versus needs work. Tag failure reasons like bad chunking or wrong modality. Fix the biggest issues first.
- Guardrails: add minimum similarity thresholds and redaction for sensitive fields. Use fallback prompts that ask for clarification when results are ambiguous.
Security privacy and governance
- Access control: tie index reads to user roles. Filter chunks by access labels at query time. Avoid leaking restricted content.
- Data handling: encrypt in transit and at rest, always. Keep audit logs for who accessed what and when.
- PII awareness: tag sensitive material during ingestion, like emails or phone numbers. Redact or restrict as needed.
- Lifecycle management: set retention policies and purge vectors when a document is deleted. Maintain a tombstone log so you can trace removals.
This isn’t busywork. Clean governance speeds legal reviews and keeps your rollout unblocked.
Pitfalls to avoid
- Overlapping indexes by modality: if you keep separate indexes, you’ll reconcile ranks for months. Start unified.
- Monster chunks: 10-page chunks or 2-minute clips seem efficient. They kill precision. Keep chunks tight and meaningful.
- Ignoring metadata: just vectors feels elegant, until you need date or product filters. Metadata is your friend.
- Silent drift: as content grows, index recall can quietly slip. Schedule periodic re-evaluation and re-indexing.
- One-shot dimension choice: set up an A/B for dimensions. Let metrics, not opinions, pick winners.
Real world plays
E commerce describe it
A shopper types, “sleek black running shoes with reflective strip like the Vaporfly, under $120.” Nova embeds the query, then matches product images, lifestyle photos, and spec sheets in one hop. You show the right images and specs. An LLM summarizes fit and care from reviews. This is the “amazon nova multimodal embeddings RAG semantic search example” you can demo to any VP in five minutes.
Bonus: handle user-uploaded images for “find similar.” Handle natural-language follow-ups like “show men’s sizes with wide toe box.” One vector space makes image-to-text and text-to-image retrieval symmetric and predictable.
Media and entertainment archive
You’ve got a decade of shows, podcast episodes, and promo clips. With Nova, producers search, “the episode where the guest explains ‘fallacy of sunk cost’ while gesturing at a whiteboard.” Retrieve the exact 25-second clip and the transcript snippet. Editors stitch faster. Fans get better search inside your app.
A content lead put it best. “Our creators don’t remember filenames; they remember moments.” Cross-modal vectors find moments.
Enterprise docs compliance
Financial and legal teams live in PDFs packed with charts, footnotes, and tables. Nova maps the chart image and the paragraph that explains it into the same space. A compliance analyst can ask, “Show the stress-test chart where Tier 1 capital dips below 10% and the note that explains why.” The system returns both.
Working in SAP landscapes? You can embed policy PDFs, export table screenshots, and training videos. Then wire Nova’s vectors into your existing governance portal. That satisfies “amazon nova sap” style needs without a platform overhaul.
Customer support resolve faster
Agents and bots pull answers from screenshots, how-to videos, and long KB articles. With a single embedding space, a user can ask, “Why does login keep failing with code 8127?” They get a screenshot of the exact dialog. They get the paragraph that explains the fix. They also get a 15-second clip showing the steps. Less bouncing between tools. More first-contact resolution.
Pulse check what to remember
- One model, all modalities: text, docs, images, video, and audio in a single space.
- 8K-token text and 30s media segments; segment larger assets.
- Synchronous for real-time; async for “nova batch inference” at scale.
- Dimensionality choice equals accuracy versus cost. Benchmark on your data.
- Tagging and rerank beats monolithic scores. Hybrid search helps rare terms.
- Multimodal evidence improves RAG grounding and user trust.
Cost and performance playbook
- Start small: embed a single product line or one department’s docs. Measure baseline recall, MRR, p95 latency, and cost per query.
- Scale smart: shard by business unit or modality if memory runs tight. Keep a global router that knows where to look first.
- Cache everywhere: cache query embeddings and top-K neighbors for popular questions. Most users ask the same 100 things.
- Monitor drift: track the percent of queries with no good results. If it creeps up, revisit chunking or retraining.
- Keep a rollback plan: version your indexes. If a new ingest corrupts results, flip back fast.
FAQ straight answers
What is Amazon Nova Embeddings
It’s an embedding model in Amazon Bedrock. It converts text, documents, images, video, and audio into vectors in one unified space. You use those vectors for semantic search, cross-modal retrieval, and RAG pipelines.
Where is Nova available
Per AWS, it’s available in the US East (N. Virginia) region via Amazon Bedrock. You invoke it through Bedrock’s managed runtime without provisioning infrastructure.
What are the input limits
Nova supports up to 8K tokens for text and document inputs. It supports video or audio segments up to 30 seconds. For longer content, segment into chunks and embed each chunk. Retrieval stitches relevant chunks at query time.
Synchronous and asynchronous usage difference
Use the synchronous API for near real-time scenarios like chat, agent loops, or interactive search. Use the asynchronous API for high-volume or large-file processing. Think “nova batch inference” overnight jobs that index a media library or a compliance archive.
Balance accuracy and cost
Choose the embedding dimensionality that fits your goals. Higher dimensions can improve recall and ranking, but increase storage and latency. Benchmark on your own corpus. Measure recall@K, MRR, and nDCG. Pick the minimal dimension that meets your quality bar.
Use Nova with enterprise systems
Yes. Nova outputs standard vectors you can store in your preferred vector database. Associate them with records from systems like SAP. You’re not changing SAP. You’re augmenting search and RAG over exported documents, images, and media.
Need a new vector database
Not necessarily. Many teams start with what they already run. OpenSearch k-NN, PostgreSQL with pgvector, or a managed vector service. The key is support for your similarity metric, metadata filters, and hybrid search. Start with the simplest option your team can operate.
Handle updates and deletions
Treat your index like a source of truth with versioning. When a document changes, write a new version and mark old chunks inactive. Run a background purge. For deletions, remove vectors and invalidate caches right away. Keep a lightweight audit trail for compliance and debugging.
What about multilingual content
If your corpus spans multiple languages, store language as metadata. Evaluate retrieval quality per language. You can route queries through translation for consistency, or keep parallel indexes. Measure with a multilingual test set before you scale.
Tips to reduce latency
Keep chunk sizes tight. Retrieve fewer but higher-precision candidates, like top-20. Push heavy rerankers off the critical path. Precompute and cache embeddings for common queries. Use streaming responses so users see partial results fast, then refine.
Ship this fast multimodal RAG
1) Ingest: collect PDFs, slide decks, images, and short video or audio clips. Extract text and captions.
2) Chunk: 1–2 paragraph text chunks. 20–30 second media chunks aligned to scenes. Pair charts with captions.
3) Embed: call Nova via Bedrock. Pick a dimension that fits your budget.
4) Index: store vectors and metadata like modality, source, and timestamps in your vector DB. Enable hybrid search.
5) Retrieve: top-K by vector similarity. Then rerank with metadata rules.
6) Generate: feed multimodal evidence into your LLM. Cite timestamps and pages.
7) Evaluate: track recall@K, MRR, latency, and cost per query. Iterate.
You don’t need a forklift upgrade. Start with one journey, like e-commerce search or policy Q&A, then scale.
Here’s the takeaway. The gap between “we have all this content” and “users can find what matters” is no longer a moat of glue code. With Nova, you collapse modalities into one language, vectors. Then let search and RAG do the rest. If you’ve been waiting for a simple, accurate, affordable way to unify retrieval across formats, this is the green light.
If you want help pressure-testing queries and tightening retrieval quality, take a look at Requery.
For real-world outcomes and patterns you can borrow, explore our Case Studies.
References
- Amazon Bedrock documentation: What is Amazon Bedrock?
- IBM: What is unstructured data?
- OpenAI CLIP (context on cross-modal embeddings)
- Amazon OpenSearch Service: k-NN (vector) search documentation
- AWS Global Infrastructure (regions)
- Amazon Bedrock: Batch inference (asynchronous)
- Amazon Bedrock: Security and compliance
- FAISS: A library for efficient similarity search
- HNSW: Efficient and robust approximate nearest neighbor search
- Okapi BM25 overview (sparse retrieval)
- Discounted cumulative gain (nDCG)
- WebRTC Voice Activity Detection (VAD)
- PySceneDetect (video scene detection)
- pgvector: Open-source vector similarity for Postgres
- Pinecone documentation