

You don’t build AI with vibes. You build it with compute, data pipes, and tough governance. The newest AWS roundup leans into that truth: massive scale with Project Rainier, new power via Amazon Nova and Bedrock, and a global push to make AI safer, faster, and actually shippable.
Here’s the punchline: your AI dreams die without infrastructure. And not just any kind—cloud-native, security-first, and tuned for ML jobs that chew billions of tokens or trillion-parameter weights.
If slides bore you and you want receipts, stick around. You’ll leave with a clear AI infra definition, an innovation checklist, and real patterns you can ship on AWS today. Zero fluff, maximum signal.
Want to see how teams are already shipping? Browse our real-world outcomes in Case Studies.
Quick note before we dive in: this isn’t a theory drop. It’s a field guide you can use to stand up aws ai infrastructure this week—what services to pick, how to wire them, and where to put guardrails so your launch doesn’t explode at 2 a.m.
TLDR
- AI at scale is an infrastructure problem first, model problem second.
- AWS is scaling hard (Project Rainier, Amazon Nova, Bedrock) with global AI infra and responsible AI tools.
- Governance is a feature, not a tax: bake guardrails in from day one.
- Copy-paste patterns: RAG on Bedrock + OpenSearch, MLOps on SageMaker, and AIOps for cost and reliability.
- Start lean: instrument everything, control blast radius, automate compliance.
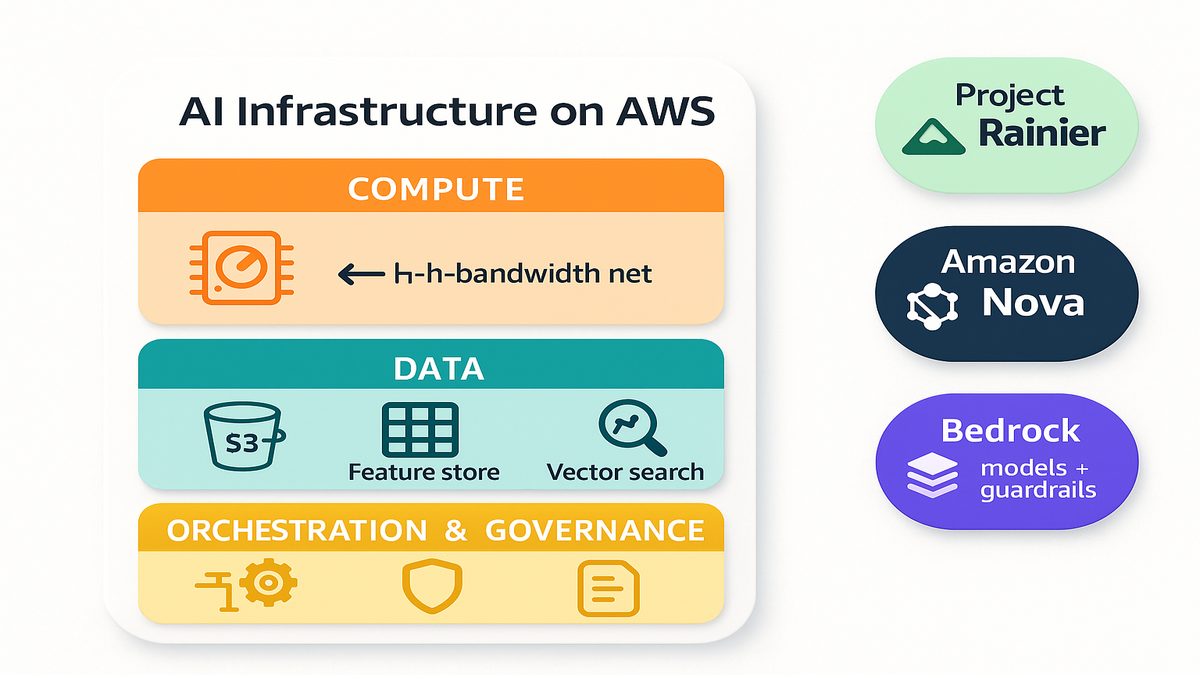
What AI infrastructure means
Three layers you can’t skip
AI infrastructure isn’t a buzzword—it’s the scaffolding that turns a smart demo into a real product. Think in three layers:
- Compute: accelerators (GPUs or AI chips), high-bandwidth networks, distributed training and inference.
- Data: durable storage, feature pipelines, vector search, lineage.
- Orchestration and governance: deployment flows, observability, security, and policy.
On AWS, those turn concrete: EC2 and accelerated instances for training and inference; Amazon S3 and purpose-built stores; Amazon OpenSearch Service for vector search; and orchestration with SageMaker, Step Functions, and container stacks. Bedrock adds managed access to foundation models and guardrails, while IAM, CloudTrail, and Control Tower enforce least privilege and compliance.
Add a mental model: data flows from S3 (golden source) into pipelines (Glue or Step Functions) that produce features and embeddings. Those land in OpenSearch for vector recall. Your apps hit endpoints (SageMaker or Bedrock) with observability (CloudWatch, X-Ray) and policy controls (IAM, CloudTrail). Each hop is secured, logged, and costed.
A good litmus test: could a new teammate look at your diagram and answer “Where’s the data? Where’s the model? Where’s the evidence?” If they can’t, your ai cloud infrastructure needs clearer lanes.
Why the definition matters
If you’re asking “what is an AI infrastructure?” it’s this: a cloud-native system that reliably moves data to models (and back), at a price and performance you can live with, under controls regulators will sign. Or as Andrew Ng said, “AI is the new electricity”—you need a grid before you light the city.
The stakes aren’t theoretical. McKinsey says generative AI could add $2.6–$4.4T in value each year. You won’t see any of that if your endpoints die on launch day or your data governance fails audit.
Make it practical: define SLOs for latency and accuracy, name budgets up front, and decide the blast radius you’ll accept. Then pick services that enforce those limits by default. That’s how infrastructure becomes momentum, not overhead.
AWS bet Rainier Nova Bedrock
Project Rainier at a glance
AWS’s weekly roundup shows an aggressive scale-up via Project Rainier—custom compute clusters for industrial AI workloads. Translation: larger clusters, tighter networks, and more predictable throughput for training and huge inference farms. Think fewer noisy neighbors and more steady training runs.
Under the hood, this pairs with AWS’s building blocks like the Nitro System for isolation and performance, and high-throughput networking (think Elastic Fabric Adapter for low-latency, HPC-style comms). The outcome you care about: faster time-to-train, steadier distributed jobs, and capacity that can actually meet your ramp.
Amazon Nova in context
Alongside the hardware story, Amazon Nova signals new cloud service upgrades. While the roundup keeps details tight, the message is clear: more turnkey services for AI builders that play well with the rest of your stack—data, orchestration, and security—so you ship faster with fewer custom parts.
In practice, “turnkey” should mean: fewer glue scripts, simpler IAM permissions, tighter hooks into logs and metrics, and presets that match Well-Architected best practices. Less yak-shaving, more building.
Bedrock’s role in the stack
Amazon Bedrock keeps maturing as the simple interface for foundation models, fine-tuning, and guardrails. You pick models, enforce safety filters, and wire outputs into apps without standing up fleets. It’s also the friendliest on-ramp if you’re corralling “shadow AI” tests into something your platform team can govern.
For teams evaluating aws ai infrastructure, Bedrock helps reduce the biggest headaches: model choice, safety review, and operational scaffolding. It’s not a silver bullet, but it’s the shortest path from “we have a use case” to “we have a running service with audit trails.”
Zoom out, and the AWS story is clear: scale up the iron (compute and network), package the magic (managed AI services), and embed safety and compliance. If you’re evaluating aws ai infrastructure, these building blocks are the backbone.
Governance security compliance velocity
Guardrails by design
Speed without guardrails is how you end up on the front page. The roundup highlights stronger tools for governance, security, and scale of AI models—useful if you want one CI/CD path for both apps and AI.
Bedrock supports model-level guardrails; IAM policies gate who can use which models and data; CloudTrail logs every call; and Amazon CloudWatch plus AWS X-Ray give you the traces to tie bad outputs back to prompts, parameters, or data sources.
As NIST puts it in the AI Risk Management Framework, trustworthy AI should be “valid and reliable, safe, secure, and resilient.” Build that into your architecture like it’s non-negotiable, because it is.
Operationalize it:
- Define allowed and disallowed inputs. Turn on Bedrock guardrails to enforce content limits.
- Require signed requests with IAM roles and short-lived creds for every model call.
- Log prompts, responses, and safety events to a structured store (CloudWatch + S3) with data retention policies.
- Tag resources by environment, owner, and sensitivity so you can prove separation of duties.
Policy as code everywhere
Use organization-wide baselines with AWS Organizations and Control Tower. Treat PII handling as code with Macie and auto remediation via EventBridge + Lambda. For model risk, track datasets, versions, and eval thresholds in a registry (SageMaker Model Registry works) and gate promotions with Step Functions approval steps.
If your stack includes Amazon Marketing Cloud, our AMC Cloud can speed privacy-safe analytics and automation on AWS.
Security isn’t a bolt-on. It’s your ability to keep shipping. The teams that win translate governance into automated pipelines. Do that, and audits become evidence exports—not fire drills.
Add a few must-haves:
- Least privilege by default with IAM; review access via Access Analyzer.
- CloudTrail on org-wide; immutable logs stored in a locked S3 bucket.
- Vulnerability scans for container images and deps before deploy.
- Red-teaming prompts and jailbreak attempts, with transcripts captured and fixes logged.
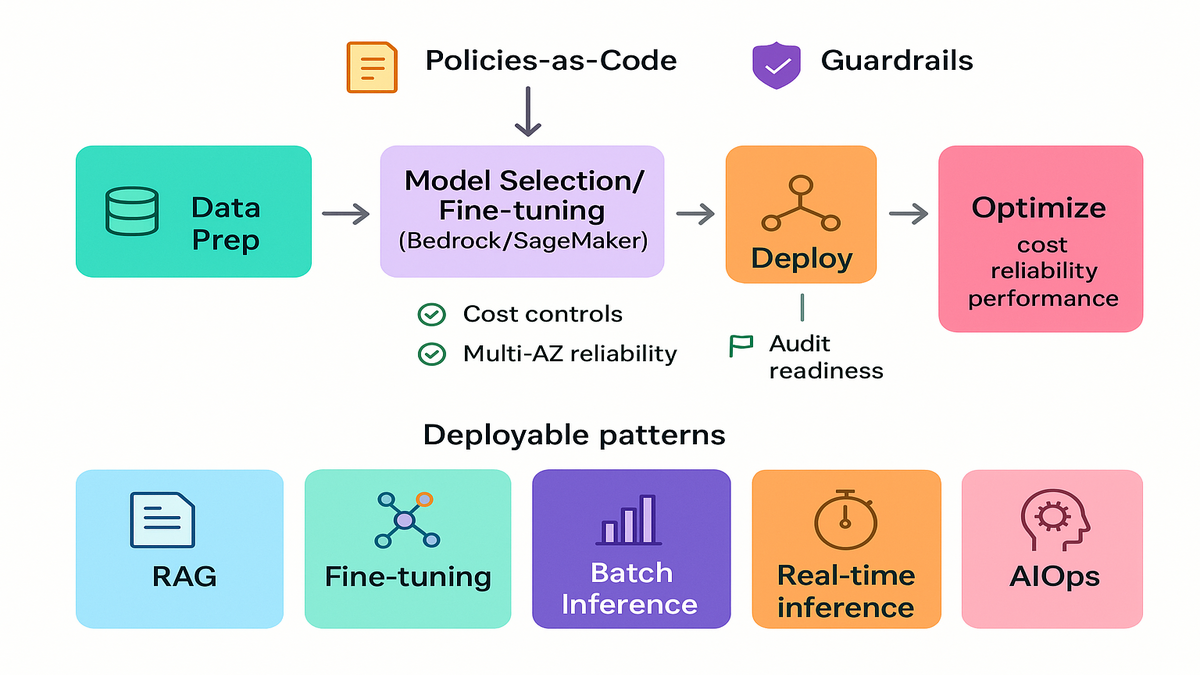
Five deployable patterns
RAG with Bedrock OpenSearch
- Use Amazon Bedrock for foundation models.
- Store embeddings and metadata in Amazon OpenSearch Service.
- Keep sources in S3, index via Lambda jobs, and add Retrieval Augmented Generation for grounded answers.
- Add managed guardrails in Bedrock to filter toxic or policy-violating content.
Make it robust:
- Use OpenSearch’s vector index with hybrid search (BM25 + vectors) for stronger recall.
- Chunk documents with semantic cuts; store chunk IDs and source URLs for citations.
- Refresh the index with an event-driven pipeline (S3 events -> EventBridge -> Lambda) so updates are near-real-time.
- Log retrieval scores and answer confidence; if confidence is low, route to a fallback template.
- Cache popular queries in ElastiCache to shave latency on hot paths.
Fine tuning loop on SageMaker
- Spin up managed training jobs with Spot instances for cost control.
- Track datasets and eval results in SageMaker Model Registry.
- Automate canary rollouts with SageMaker endpoints and blue/green traffic shifting.
Level it up:
- Version datasets and prompts in S3 with checksums; record lineage in the registry notes.
- Use distributed training only when batch size or model size demands it; otherwise you’re paying for complexity.
- Capture offline metrics (accuracy, BLEU or ROUGE) and online metrics (CTR, resolution rate) to the same dashboard.
- Include a rollback rule: if p95 latency or safety violations pass a threshold, shift traffic back in seconds.
Batch inference at scale
- Use AWS Batch or EMR on EKS to fan out long-running inference.
- Run on accelerators where needed; downshift to CPUs for lighter models.
- Emit per-item metrics to CloudWatch; throttle and retry with SQS for burstiness.
Make it industrial:
- Store work items in SQS with idempotency keys; write results to S3 with a manifest.
- Use Batch job queues with different compute environments (Spot and On-Demand) for price and perf mixing.
- Emit custom metrics per thousand items processed, error counts, and retries; alert on trends, not one-offs.
- If outputs feed analytics, partition S3 paths by date and hour for efficient downstream queries.
Real time inference low latency
- Put endpoints behind Amazon API Gateway + Lambda authorizers.
- Use provisioned concurrency or multi-model endpoints for spiky loads.
- Cache frequent prompts and responses in ElastiCache to shave milliseconds.
Go faster safely:
- Compress payloads and keep prompts tight; tokens cost money and time.
- Co-locate endpoints and data in the same Region and VPC; remove cross-AZ traffic if your SLOs allow.
- Add circuit breakers: if the model is slow, return a cached or rule-based fallback.
- Use X-Ray traces to spot cold starts, slow deps, and noisy neighbors.
AI for infrastructure management
- Feed CloudWatch logs and metrics to anomaly detection.
- Use Amazon DevOps Guru and look for automated insights.
- Triage incidents with Bedrock-powered summarization bots that turn noisy alerts into action.
Ship the human-in-the-loop:
- Summarize incident context, recent deploys, and likely root causes; include runbook links.
- Auto-create tickets with structured fields, not free text. Make handoffs 10x cleaner.
- Track mean-time-to-detect (MTTD) and mean-time-to-recover (MTTR) as first-class metrics.
These are practical ai infrastructure examples you can ship this quarter.
Fast recap for movers
- Infrastructure first: compute, data, orchestration and governance.
- AWS is scaling hard (Rainier and Nova) while making AI simpler (Bedrock).
- Governance is baked in: IAM, CloudTrail, control planes, and guardrails.
- Copy the patterns: RAG, fine-tuning, batch plus real-time, and AIOps.
- Start small, automate everything, instrument by default, avoid heroics.
Build for scale
Cost discipline without downgrading ambition
Your CFO doesn’t hate AI; they hate surprise bills. Set budgets and alerts. Use Savings Plans or Reserved Instances for steady training, and Spot where interruption is fine. For retrieval, compress vectors and right-size index shards in OpenSearch. Profile prompts and responses; token counts are budget levers.
For training, consider sharding datasets to checkpoint early and often. For inference, separate cold, warm, and hot paths. Autoscale smart; don’t add capacity just because a graph looks spicy at 9 a.m.
Add the basics:
- Stand up AWS Budgets and Cost Explorer on day one; tag by project and environment.
- Use Compute Optimizer to right-size instances; don’t assume “bigger means faster.”
- Prefer short-lived jobs on Spot for non-urgent work; checkpoint so preemption is a shrug, not a disaster.
Reliability patterns save launch
Design for blast-radius control. Keep training in one account, staging in another, prod in a third. Use multi-AZ by default for endpoints, and multi-Region if your SLOs need it. Put circuit breakers in front of model calls; return graceful fallbacks when a model is slow or down.
Extra patterns:
- Health-check every dependency (feature store, vector DB, model endpoint). If one fails, degrade gracefully.
- Keep runbooks close to alerts; every PagerDuty ping should include a link to “do this next.”
- Practice game days. Break things on purpose in staging and verify your guardrails hold.
Performance where it matters
Low-latency inference depends on network and payloads. Co-locate compute and data, compress inputs, and pre or post-process near the model. For distributed training, use high-throughput networking and topology-aware placement. A bit of system tuning often beats tweaking model layers.
Performance checklist:
- Keep p95 and p99 latency targets explicit; staff to those, not averages.
- Use EFA-enabled clusters for large distributed jobs when all-reduce starts to dominate.
- Warm your endpoints before big events; don’t find cold starts during your launch demo.
The goal: predictable cost, predictable performance, and predictable outcomes.
Where AWS is pushing next
Global scale and ethical rails
The roundup calls out expansion of AI-focused infra worldwide and partnerships with AI safety and research groups. Read that as lower latency in more Regions and more alignment with new rules for safe, ethical AI.
If you operate across borders, align now with frameworks like NIST’s AI RMF and map controls to your AWS stack. Document your model lifecycle: data sourcing, eval metrics, drift detection, rollback rules. Store all that metadata so audits are a lookup, not a rebuild.
Pro move: map your controls to Well-Architected (Security, Reliability, Cost) and the Machine Learning Lens. That gives your team a shared language and a repeatable playbook.
Practical next moves
- Standardize your platform: pick a small set of services and patterns and make them paved roads.
- Centralize secrets and config; templatize deployments with IaC (CloudFormation or Terraform).
- Instrument end-to-end: prompts, responses, latency, costs, guardrail triggers, and user feedback.
- Define data residency and retention rules per Region; document where each dataset can and cannot live.
- Establish an experiment registry: what you tried, what worked, what failed, and the evidence.
As the stack gets bigger (Rainier), the services more capable (Nova, Bedrock), and the rules tighter (governance tooling), your job is to reduce variance and boost repeatability. That’s how you scale wins.
FAQs to keep you moving
What is an AI infrastructure
AI infrastructure is the cloud-native base that runs your models and pipelines—compute (accelerators and networking), data (storage, features, vector search), and orchestration or governance (deployments, observability, security, compliance). If you’re searching “what is an ai infrastructure,” that’s the working definition you can build against.
How AWS approaching AI infrastructure
According to the latest roundup, AWS is scaling custom-built compute clusters via Project Rainier, enhancing cloud services through Amazon Nova, and expanding managed AI via Amazon Bedrock. It’s all wrapped in stronger governance, security, and global reach so enterprises can deploy at scale, responsibly.
Need GPUs for everything
No. Use accelerators for training large models or latency-sensitive inference. For smaller models and batch inference, CPUs can be fine and cheaper. The trick is workload fit—match hardware to the job, not the hype.
Secure generative AI without slowing
Automate controls. Use IAM for least privilege, CloudTrail for auditable logs, and guardrails in Bedrock for content safety. Gate model promotion via CI or CD with approvals and evaluation thresholds. Governance should be pipelines and policies, not meetings and memos.
AI cloud infrastructure innovations examples
Start with Retrieval Augmented Generation on Bedrock + OpenSearch, fine-tuning on SageMaker with a model registry, batch inference on AWS Batch or EMR on EKS, and AIOps that uses anomaly detection plus summarization bots. Those four cover 80% of common enterprise needs.
Where Nova and Rainier fit
Rainier is about large-scale, purpose-built compute clusters for heavy AI workloads. Nova points to enhanced cloud services that simplify building and running AI systems. Pair them with Bedrock if you want a managed model-access layer with built-in guardrails.
Measure model quality in production
Track both offline and online metrics. Offline: accuracy, BLEU or ROUGE, toxicity rate. Online: task success, conversion, resolution time, and user feedback. Pipe metrics to CloudWatch and link them to deployment versions in SageMaker Model Registry so you can prove why a model is in prod.
Data residency and compliance
Decide where data can live (by Region) and enforce it with account boundaries, S3 bucket policies, and IaC. Use AWS Organizations SCPs to block out-of-policy Regions. Document retention and deletion timelines and automate them.
Forecast control cost before launch
Estimate request volume, average token counts, and model latency. Set budgets in AWS Budgets, build dashboards in Cost Explorer, and put hard alarms on weekly spend. For training, run a small pilot with Spot to validate runtime and checkpoint timing before scaling up.
Ship this week
- Define your use case and SLOs; set budgets and guardrail policies up front.
- Stand up data: S3 for sources, OpenSearch for vectors, and data lineage tracking.
- Pick models in Amazon Bedrock; enable safety guardrails and evaluation metrics.
- Build pipelines: IaC templates, CI or CD to deploy endpoints, canary rollouts.
- Instrument everything: CloudWatch, CloudTrail, and structured logs for prompts and results.
- Run a red-team pass; document risks and fixes; set rollback criteria.
Optional adds that pay off fast:
- Create a shared “paved road” template repo with Terraform or CloudFormation for the patterns above.
- Wire alerts to chat with short, human-readable summaries (title, impact, next step).
- Add a weekly ops review: cost deltas, safety incidents, drift signals, and upcoming launches.
You don’t need a 50-slide strategy to get moving—you need a paved road and a few smart limits. AWS’s direction is obvious: bigger clusters, simpler services, stronger guardrails. Your leverage comes from pattern discipline. Pick two or three patterns, codify them, and make them the default.
The companies that win won’t be the ones with the fanciest demos. They’ll be the ones who can ship safe, fast, repeatable AI—week after week—without blowing up their budget or their risk register.
References
- McKinsey: The economic potential of generative AI
- NIST AI Risk Management Framework 1.0
- AWS Global Infrastructure
- Amazon Bedrock
- Bedrock Guardrails
- AWS Responsible AI
- AWS Identity and Access Management (IAM)
- AWS CloudTrail
- Amazon CloudWatch
- AWS X-Ray
- AWS Control Tower
- AWS Organizations
- Amazon Macie
- Amazon EventBridge
- Amazon Simple Queue Service (SQS)
- Amazon Simple Storage Service (S3)
- AWS Step Functions
- Amazon SageMaker
- SageMaker Model Registry
- AWS Batch
- Amazon EMR on EKS
- Amazon OpenSearch Service
- Amazon API Gateway
- AWS Lambda
- Amazon ElastiCache
- Amazon DevOps Guru
- AWS Savings Plans
- Amazon EC2 Spot Instances
- AWS Budgets
- AWS Cost Explorer
- AWS Compute Optimizer
- AWS Nitro System
- Elastic Fabric Adapter (EFA)
- Amazon EC2 P5 Instances
- AWS Well-Architected Framework: Security Pillar
- AWS Well-Architected Framework: Reliability Pillar
- AWS Well-Architected Framework: Cost Optimization Pillar
- AWS Well-Architected Machine Learning Lens
- AWS Data Residency
- Amazon CloudWatch Anomaly Detection
- AWS Glue
