

Amazon's recent update to S3 is shaking things up for anyone knee-deep in big data analysis using Apache Iceberg. They've unleashed two robust compaction strategies: 'sort' and 'z-order.' These shiny new tools promise to turbocharge your query performance by a staggering threefold compared to the classic 'binpack' method.
It's like upgrading from a bicycle to a motorbike when you're zipping through those colossal datasets that used to slow you down.
Now, let's dive into these strategies. Imagine you’re on a treasure hunt, but instead of sifting through endless sand to find your prize, the data is pre-organized so your search is swift and efficient. That’s exactly what these compaction strategies do—they cluster similar data together. So, when it's time to query, your system knows exactly where to look, avoiding a wild goose chase through irrelevant data files.
If you're thinking about integrating these strategies into your S3 Tables or general-purpose buckets, you’re in luck. Amazon's latest system comes to the rescue, incorporating these improvements as part of your regular service. There's no extra fee to worry about, though you should anticipate some compute costs when carrying out compactions.
Key Takeaways
- Sort and Z-order Compaction: Utilize these strategies to boost performance by minimizing file scans during queries.
- Apache Iceberg Use-case: These strategies are perfect for managing large datasets that require frequent updates.
- No Extra Cost: Implementing these improvements won't add to your AWS bill—be prepared for compute costs during compaction, though.
- Real-world Impact: You can expect up to threefold performance improvements on queries, turning sluggish tasks into quick operations.
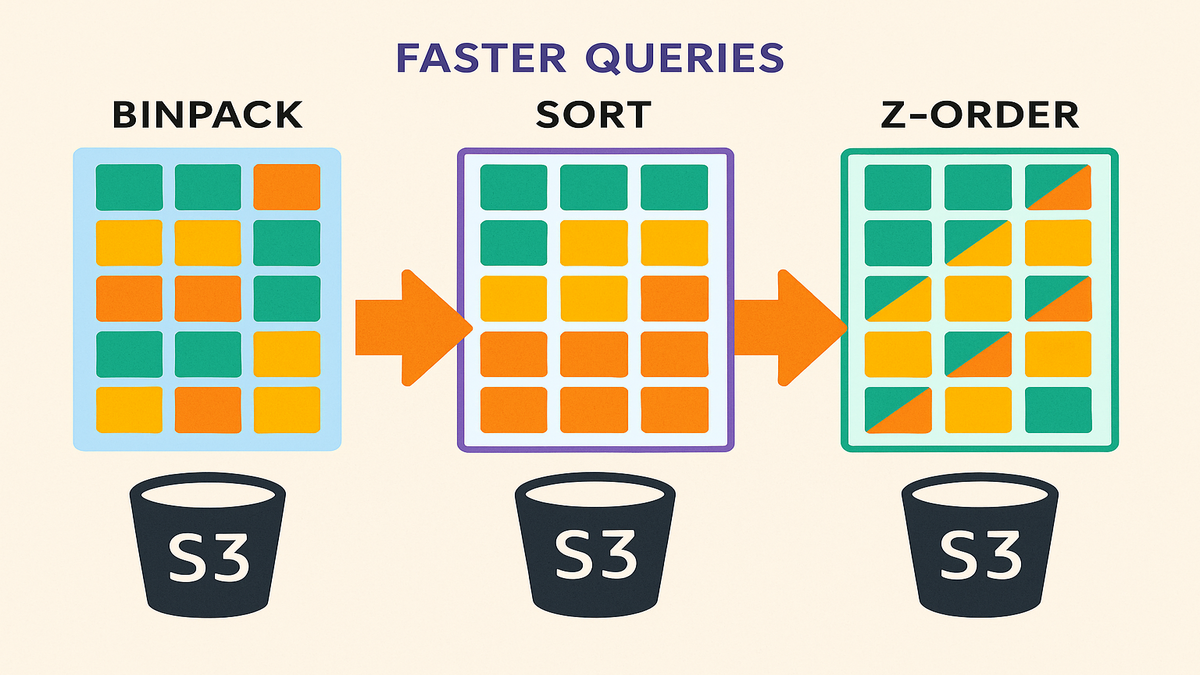
Breaking Down New Strategies
Sort vs. Binpack Basics
The go-to 'binpack' compaction strategy is decent when it comes to saving query performance in managed S3 Tables. But, the 'sort' strategy elevates that experience. It allows you to organize files based on a customized column order, making the query engine's task as straightforward as flipping through a neatly organized photo album rather than a jumbled scrap heap.
Use Case Snapshots:
- Example 1: Suppose you've organized a table by
stateandzip_code. Queries targeting these categories become a walk in the park, as they're quick and efficient rather than a hunt for an obscure artefact. - Example 2: When you're filtering across multiple dimensions, like identifying customers by
pickup_locationanddropoff_location, this pre-arrangement significantly narrows down what your systems have to sift through, akin to cutting the fat off a steak.
Z-Order: Why It Matters
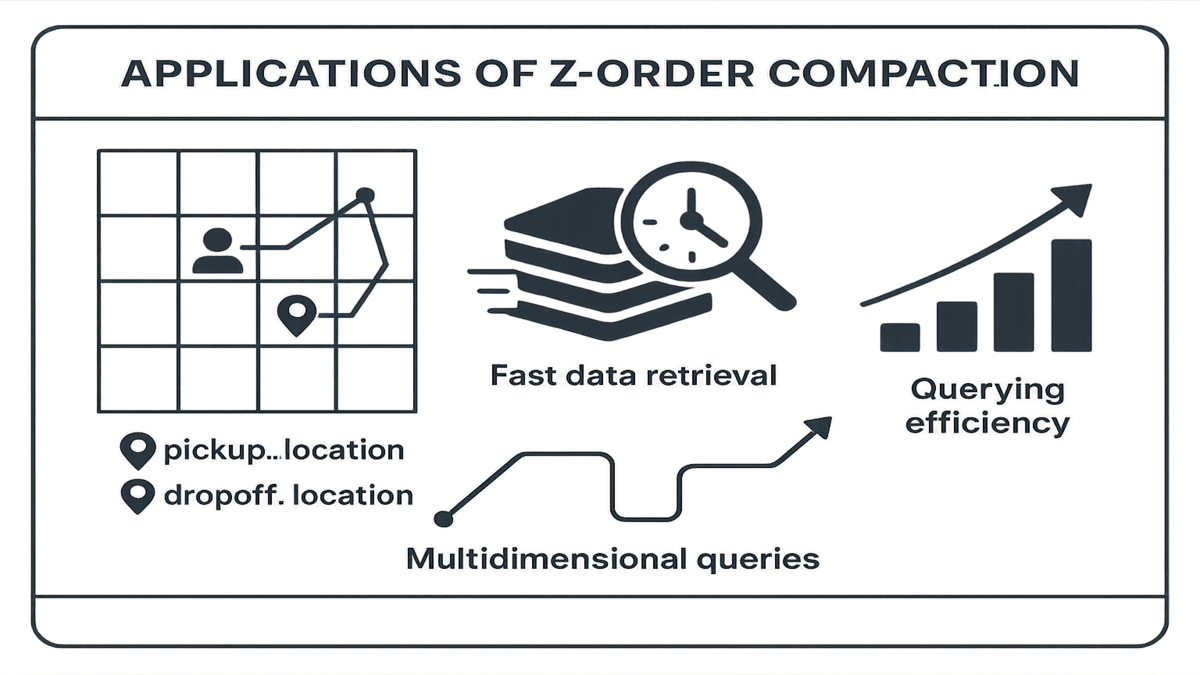
Delving into Z-order might initially feel like solving a cryptic crossword puzzle, but the benefits are monumental. This strategy interleaves values from multiple columns, yielding compounded gains particularly in scenarios involving multiple dimensions.
Practical Applications:
- Spatial or Multi-Dimensional Queries: When queries simultaneously utilize multiple dimensions, such as
pickup_location,dropoff_location, orfare_amount, the Z-order strategy ensures a speedy data retrieval process instead of a long, grueling race.
For more advanced tactics and successful client stories, check out our Case Studies.
Why Consider This Upgrade
If implemented correctly, these strategies considerably reduce the number of files the query engine needs to evaluate. This reduction not only saves time but also slashes potential costs in cloud storage. These new methods are crafted to outpace the older sort and binpack strategies and have become a hot ticket item for data scientists eager for performance bursts.
Snapshot of Progress
- Streamlined Process: Data management has never felt this light, with constant updates burdening the system less.
- Performance Gains: Users have reported noticeably quicker query responses during hands-on trials, notably when working with Apache Spark tables.
FAQ Huddle
What’s the cost involved with using these strategies? There are no additional charges beyond regular S3 usage and upkeep fees, although compute costs do apply during the Data Catalog's compaction process.
Do these strategies apply to pre-existing tables? Any new data written after you activate these strategies will adapt instantly, whereas older compacted files stay unchanged unless rewritten.
How do I implement Z-order compaction? For Z-order deployment with S3 Tables, update your table maintenance settings through the S3 Tables API.
Are these strategies universally available? Yes, these strategies are available in every AWS region that supports Glue Data Catalog optimizations.
What real-world impact can I expect? Look forward to significant improvements in query processing times and monetary savings, potentially tripling those seen with binpack strategy, delivering efficiency assertions both in time and resources.
Leverage the Compaction Boost
Start by ensuring your table has a defined sort order; if not, create one. Then, with the proper permissions and configurations, tweak your compaction settings using the AWS Glue Data Catalog for general-purpose buckets or through the S3 Tables API.
Innovation in data management is a constantly moving target. With the introduction of sort and z-order strategies, Amazon Web Services is laying down a foundation for quicker, smarter data queries, transforming the way you manage and engage with large datasets in the cloud. Are you ready to step into this new paradigm and discover what these enhancements can do for your data lake processes?
For more insights and detailed guides, explore our AWS guide on Cloud Data Management and stay ahead of trends in data strategy.