

You don’t fix a 30-year-old mainframe by duct taping APIs on it. You reimagine it instead. That’s the leap from “we migrated” to “we move faster than the market.”
Here’s the twist. An AI-led reimagine move doesn’t just port COBOL. It rebuilds the app into event-driven microservices. It extracts business logic you can’t afford to lose. It gives you data lineage so you’re not refactoring blind.
If you’ve been hunting for reimagine help on Reddit, this is your field guide. Or collecting “examples that actually work,” same thing here. We’ll show how teams use AWS patterns. Think microservices, real-time functions, and generated docs. They turn monoliths into systems you can ship and scale.
And yes, you keep the core logic your business runs on. You just make it faster, safer, and cheaper to change.
Think of it like moving from a flip phone to a smartphone. Same contacts, way more capability. You’re not rewriting history. You’re upgrading how the business thinks, ships, and learns.
This guide keeps it real. Concrete patterns, pitfalls to dodge, and a 30-day pilot you can run. No hype. Just a repeatable playbook your team can copy and adapt.
TLDR
- Reimagine > refactor: you redesign the app, not only the codebase.
- AI analysis plus org knowledge preserves core business rules during rebuild.
- Data lineage and automated data dictionaries stop broken assumptions.
- Event-driven microservices replace brittle batch jobs for agility.
- Generated, end-to-end docs align architects, devs, and business owners.
- Start with a tight pilot, instrument everything, and iterate fast.
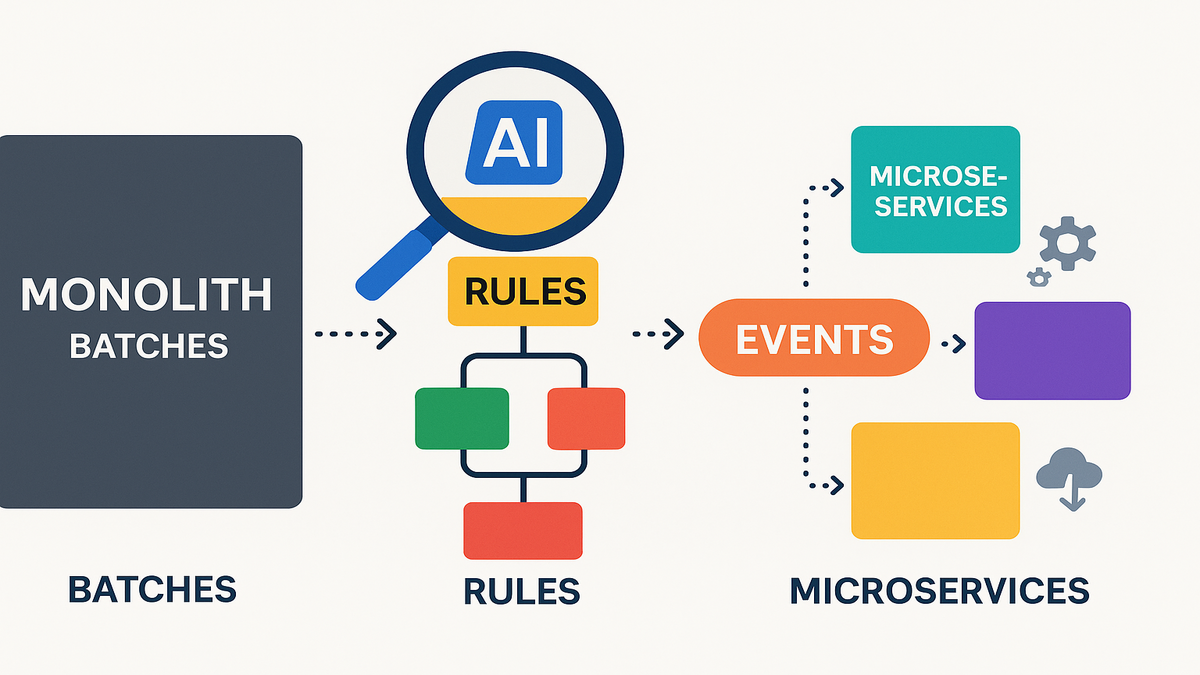
Reimagine vs migrate
Monolith to events
The reimagine path transforms legacy mainframe apps, not just ports them. Instead of lifting JCL-driven batch jobs and hoping for the best, you split them into cloud-native microservices triggered by events. For example, a nightly claims batch becomes real-time events. Files land in Amazon S3. Events route with Amazon EventBridge. AWS Step Functions orchestrate the flow. Steps run in parallel on AWS Lambda or containerized services.
This shift turns a big-bang batch into bite-sized, observable work units. You gain auto scaling, fault isolation, and the freedom to ship changes independently.
Under the hood
- Idempotency becomes a first-class rule so retries don’t double charge or double notify.
- Ordering is handled on purpose, with state machines or FIFO queues where needed.
- Backpressure is managed with queues and dead-letter policies, not 3 a.m. firefights.
- Failures are contained. One bad event hurts only that message, not the job.
A practical pattern looks like this. S3 to EventBridge for fan out. SQS for buffering and retry control. Step Functions for orchestration. Lambda or ECS for compute. You can scale hot paths without scaling the whole estate.
Logic stays intact
Reimagine does not mean “throw out the rules.” You extract the rules with AI-assisted analysis and institutional knowledge. The approach described as AWS Transform blends deep system analysis with your subject experts. It produces accurate business and technical docs. You get a clear map of decision tables, checks, and domain workflows before touching architecture.
First-hand example. A pension calculation module with dense COBOL paragraphs gets documented. It becomes modular decision trees and sequence diagrams. Engineers implement these as stateless services with well tested rules in code. Business stakeholders can validate the logic in plain language.
Protect logic
- Build a golden dataset with known inputs and outputs from the mainframe.
- Convert business rules into unit tests and contract tests, not only requirements docs.
- Use decision tables and rules engines only where they cut complexity. Keep most rules as readable code with tests.
- Hold short SME workshops, 60–90 minutes, to confirm edge cases stuck in people’s heads.
When rules live as tests, they travel with the system. That’s how you make change safe.
Data as north star
Map real flows
Legacy systems hide business rules inside copybooks, JCL, and odd file layouts. Reimagine forces clarity with data lineage across jobs and datasets. You trace which jobs produce which files. You track which programs change which fields. You map how downstream consumers rely on each column before redesigning schemas.
Practically, you catalog sources. For example, VSAM exports into Amazon S3. You crawl them with AWS Glue to identify structures. You visualize lineage with Amazon DataZone to see upstream and downstream blast radius. That lets you refactor with confidence, not superstition.
Automate data dictionary
You also generate an automated data dictionary. Every field gets a source, description, and owner. That dictionary becomes the contract for your new data plan. Maybe Amazon Aurora or Amazon DynamoDB for ops data. Amazon S3 plus Athena for analytics.
First-hand example. A billing workload exposes fixed-length COBOL files. You crawl to infer schema. You map to normalized tables with constraints. You add lineage diagrams showing how each downstream report is produced. When you cut over, you know which dashboards to verify. You know which consumers to notify and which transforms to re-run.
References on AWS. Glue crawlers for schema discovery. DataZone lineage for impact analysis. EventBridge for data-change events.
Safe schema changes
- Track schemas with a registry so producers and consumers negotiate changes with versions.
- Tag sensitive fields, like PII or PHI, and enforce encryption and masking.
- Add data quality checks, like null rates and valid ranges, to catch regressions early.
- Keep OLTP and analytics separate so reports don’t drive transactional design.
Data lineage plus a live dictionary gives you speed without breaking trust.
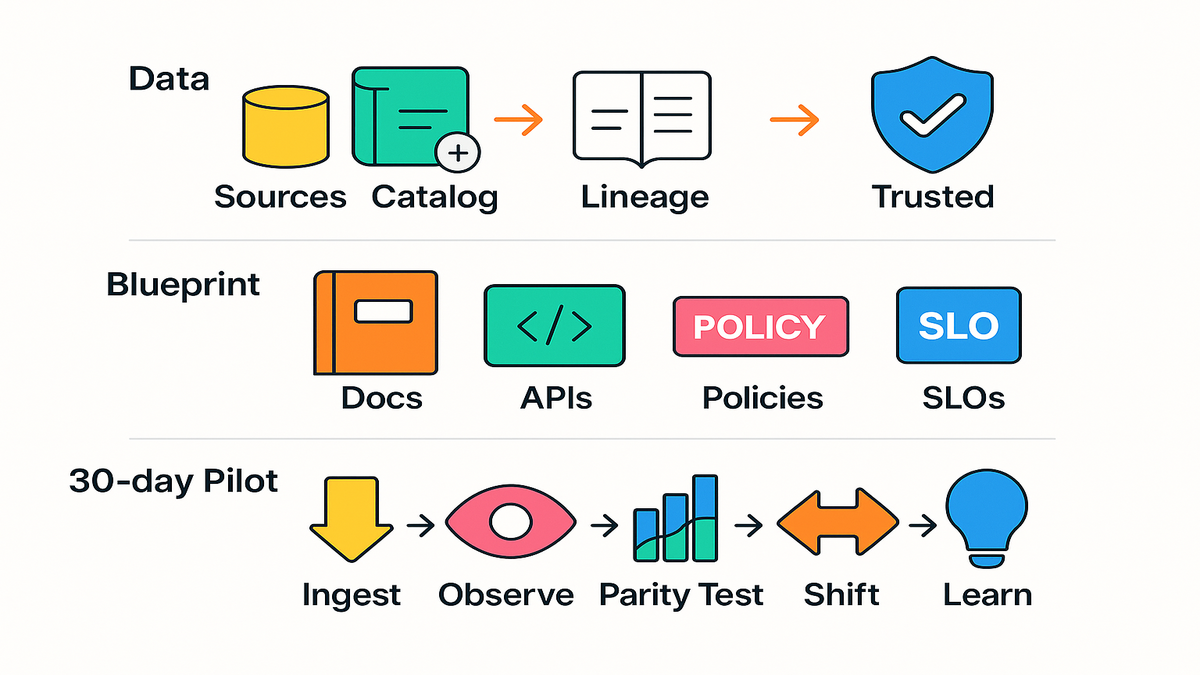
Useful documentation
Generate blueprints
Good docs are usually the first casualty in migrations. Reimagine flips that by generating end-to-end modernization docs as part of the work. The pattern described as AWS Transform creates complete artifacts. Current-state maps. Target architectures. Sequence diagrams. Domain models. API contracts.
This is not busywork. It keeps parallel teams aligned. It simplifies security reviews. It de-risks change control. It also lets non-technical leaders confirm the modern system still enforces the rules that protect revenue.
Align business and tech
When product, compliance, and engineering share one living blueprint, you decide faster. You link each microservice to the original business capability. You link each data transform to a policy. You link each SLA to a real system SLO.
First-hand example. A policy issuance flow becomes a domain-driven set of services. Quote, underwriting, bind, issue. Each with a clear API and data contract. Security and audit attach controls to the services. Operations attach SLOs to the workflows. You ship features without relitigating the whole design every sprint.
Make docs living
- Keep OpenAPI and AsyncAPI definitions in the repo, versioned with the code.
- Store diagrams as code so updates get reviewed like any change.
- Use Architecture Decision Records to capture why, not only what.
- Auto generate runbooks and onboarding checklists from pipeline metadata.
If docs live where engineers live, the repo and the pipeline, they’ll stay accurate.
AWS patterns
Microservices baseline
Event-driven microservices are the backbone of the reimagine playbook. A common baseline:
- Ingestion: Files land in Amazon S3, which generates events.
- Routing: Amazon EventBridge fans events to the right domains.
- Orchestration: AWS Step Functions coordinates multi-step flows with retries and breakers.
- Compute: AWS Lambda for bursty, stateless steps. Amazon ECS or EKS for long-running services.
- Data: Amazon Aurora for relational. DynamoDB for key value. S3 plus Athena for analytics. Amazon OpenSearch Service for search.
- Observability: Amazon CloudWatch metrics and logs, and AWS X-Ray tracing.
This setup turns nightly batches into steady flows. You don’t wait 24 hours to see failures.
Data first refactor
Most mainframe programs are quietly ETL. As you reimagine, split operational data paths from analytical ones. Keep OLTP in Aurora or DynamoDB. Push analytics to S3, catalog with Glue, and query with Athena. Or feed your warehouse.
First-hand example. A premium rating batch once wrote to flat files. Now it publishes domain events like QuoteCalculated and PolicyIssued. Microservices consume those events. They also land in S3 for analytics. Auditors can trace a premium change from event to storage to report, thanks to lineage.
You can phase this with a Strangler Fig pattern. Wrap the old system with new services. Route traffic gradually. Retire legacy modules as coverage expands.
Reliability patterns
- Transactional outbox to move from DB writes to events without losing atomicity.
- Dead-letter queues and replay tools so transient failures don’t become outages.
- Canary and blue/green deploys to cut over safely and roll back fast.
- Quotas, alarms, and circuit breakers to protect downstream systems from surges.
Build these in early. They are your seatbelts when traffic spikes or a dependency hiccups.
Halfway outcomes
- You rebuild around events, not nightly batches.
- Your business rules are documented and tested, not trapped in COBOL.
- Lineage and a data dictionary de-risk schema redesigns.
- Docs are generated as part of the work, not afterthoughts.
- You can explain the architecture to execs and auditors in one page.
- You have a pilot slice running with observability and rollback.
FAQ
Reimagine vs refactor
Refactor changes code structure while keeping behavior. Reimagine redesigns the architecture and the experience. You break a monolith into event-driven microservices. You rethink data flows. You automate docs and lineage so you move fast without losing rules.
Preserve business logic
Use AI-assisted system analysis plus institutional knowledge. The approach described as AWS Transform produces complete business and technical documentation before you cut code. Then you implement rules as tests and domain services. Stakeholders validate the outputs.
AWS building blocks
Common pieces: Amazon S3 for ingestion. Amazon EventBridge for events. AWS Step Functions for orchestration. AWS Lambda, ECS, or EKS for compute. Amazon Aurora and DynamoDB for data. AWS Glue and Amazon DataZone for catalog and lineage. CloudWatch and X-Ray for observability. You can also use AWS Mainframe Modernization services for refactor and replatform paths.
Batch to events risk
You lower risk with progressive delivery. Run events alongside batches. Validate outputs with parity tests. Use a Strangler Fig routing layer. Cut over domain by domain. Lineage maps and a live data dictionary reduce surprises.
Pilot timeline
A focused pilot that slices one batch into events often fits in weeks. Not months. You need tight scope, clear owners, and automated tests. The goal is learning speed and a repeatable template, not boiling the ocean.
More examples
Scan community threads for patterns, sure. But anchor choices in your domain. Use the examples here as starting points. Then validate with your data, constraints, and compliance rules.
30 day pilot plan
- Pick one batch flow with high business value and limited dependencies.
- Extract business rules. Interview SMEs, generate docs, write parity tests.
- Catalog data sources with Glue. Map lineage with DataZone.
- Design events and APIs. Define success metrics and SLOs.
- Implement ingestion (S3), routing (EventBridge), and orchestration (Step Functions).
- Build services on Lambda or ECS. Wire Aurora or DynamoDB as needed.
- Stand up observability with CloudWatch and X-Ray. Enable tracing and alerts.
- Run batches and events in parallel. Compare outputs. Fix deltas.
- Gradually shift traffic. Monitor. Document learnings as reusable templates.
You don’t modernize by hoping. You modernize by instrumenting.
Week by week snapshot
- Week 1: Scope the pilot slice. Confirm owners. Capture existing inputs and outputs. Build a golden dataset. Stand up a skeleton repo with CI/CD and a basic event bus.
- Week 2: Generate documentation from analysis. Define APIs and event schemas. Build the first service path end to end behind a feature flag.
- Week 3: Add parity tests. Wire lineage and data cataloging. Turn on observability with useful dashboards and alerts. Start parallel runs.
- Week 4: Fix deltas. Run canaries. Do a controlled cutover for a subset of traffic. Write up the template playbook for the next slice.
What to measure
- Lead time from change to deploy for the pilot path.
- Parity score, percent of outputs matching the golden dataset.
- Mean time to detect and resolve when a step fails.
- Cost per 1,000 events versus batch run cost.
- Onboarding time for a new engineer using the docs and runbooks.
Security and governance
Security is not a separate lane. It’s part of the blueprint.
- Identity and access: Least-privilege IAM roles per service. Scoped dataset access, not blanket buckets.
- Encryption: KMS for keys. Default encryption for S3, Aurora, and DynamoDB. TLS in transit everywhere.
- Secrets: Store in Secrets Manager, not env vars. Rotate on a schedule.
- Audit: CloudTrail enabled in all accounts. Structured logs with immutable storage for retention.
- Config and drift: AWS Config rules ensure encryption, logging, and tagging don’t drift.
- Data protections: Tag PII and PHI. Mask in non-prod. Apply fine-grained access to analytics.
It’s part of the blueprint.
Testing and quality
- Parity tests: Replay golden inputs through both systems. Compare outputs field by field.
- Contract tests: Validate APIs and events with schemas to catch breaking changes early.
- Replay strategy: Keep dead-letter queues and S3 archives so you can reprocess safely.
- Backfill plan: Script historical loads with checkpoints to avoid double counting.
- Chaos drills: Kill a dependency in test and confirm graceful degradation.
The goal isn’t zero bugs. It’s fast detection, safe rollback, and no surprises.
Observability
- Metrics: Emit at every step. Latency, throughput, error rate, and saturation.
- Traces: End-to-end request traces with IDs flowing through events.
- Logs: Structured logs with correlation IDs and context for easy grep.
- SLOs: Tie service-level objectives to goals like “quote time under 2s.”
- Synthetic checks: Ping critical flows nonstop, not only during business hours.
Observability tells you what happened and why. That’s how you move from firefighting to engineering.
Cost and performance
- Right size compute. Use Lambda for spiky, short tasks. Use containers for steady, long work.
- Storage classes: Choose S3 classes wisely for archives, analytics, and hot paths.
- Autoscaling: Scale on real signals like queue depth and latency, not wishes.
- Caching: Cache hot reads at the edge or in memory to cut latency and cost.
- Cost visibility: Tag everything. Set budgets and alerts by team and product.
Cost is a feature. Design it early so finance loves the new world too.
People and process
- Team topology: Align teams to business domains, not layers of the stack.
- Platform team: Offer golden paths, templates, and paved roads so app teams move fast.
- Change cadence: Small, frequent releases with checks beat quarterly big bangs.
- Shared language: Product, engineering, and compliance use the same blueprint and metrics.
Technology change fails without people change. Bring the humans along.
Anti patterns to avoid
- Lift and shift the batch as one giant container, then wonder why nothing improved.
- Rewriting rules from memory and skipping parity tests because “we know the system.”
- Pushing analytics through OLTP tables, then blaming the database for slowness.
- Docs in a slide deck no one updates.
- Over-optimizing for a tool instead of a business outcome.
If a choice makes change slower or riskier, it’s not reimagine. It’s rearrange.
The big unlock here isn’t a tool. It’s a mindset. You’re not just moving off mainframe. You’re designing a system that can adapt. New markets, new products, new regs. And still ship weekly. AI-assisted analysis helps you keep your rules. Event-driven microservices help you scale and evolve. Data lineage helps you not break trust. Start with a narrow pilot, measure everything, and turn the first win into a factory. Future you will thank present you for not just refactoring, but reimagining.
If you want a simple first move this week, do this. Pick the smallest high-value batch. Sketch the event flow on one page. Book two SME sessions. By Friday, you’ll know your golden dataset, your first event, and your parity plan. That’s momentum.
References
- AWS Mainframe Modernization service overview: AWS Mainframe Modernization service overview
- AWS Mainframe Modernization features (refactor, replatform): AWS Mainframe Modernization features (refactor, replatform)
- Amazon EventBridge documentation: Amazon EventBridge documentation
- AWS Step Functions documentation: AWS Step Functions documentation
- AWS Glue Crawlers (schema discovery): AWS Glue Crawlers (schema discovery)
- Amazon DataZone data lineage: Amazon DataZone data lineage
- Amazon Aurora overview: Amazon Aurora overview
- Amazon DynamoDB documentation: Amazon DynamoDB documentation
- AWS Lambda developer guide: AWS Lambda developer guide
- Amazon ECS documentation: Amazon ECS documentation
- Amazon EKS documentation: Amazon EKS documentation
- Amazon S3 event notifications: Amazon S3 event notifications
- Amazon SQS developer guide: Amazon SQS developer guide
- Amazon SNS developer guide: Amazon SNS developer guide
- Amazon Kinesis Data Streams: Amazon Kinesis Data Streams
- AWS Glue Schema Registry: AWS Glue Schema Registry
- Amazon Athena documentation: Amazon Athena documentation
- Amazon OpenSearch Service: Amazon OpenSearch Service
- Amazon CloudWatch: Amazon CloudWatch
- AWS X-Ray: AWS X-Ray
- AWS Key Management Service (KMS): AWS Key Management Service (KMS)
- AWS CloudTrail: AWS CloudTrail
- AWS Config: AWS Config
- AWS Secrets Manager: AWS Secrets Manager
- Strangler Fig Application pattern (Martin Fowler): Strangler Fig Application pattern (Martin Fowler)