

You don’t need another model. You need training on your data, period. And you need guardrails so agents don’t go rogue on messy customer asks. That’s the move here.
The fastest path to safe AI in prod isn’t “just add more prompts.” It’s pairing fine-tuning with policy controls and real evals. Nova Forge gives you the first piece. AgentCore’s Policy Engine delivers the second piece.
If sandbox demos burned you, and then collapsed in prod, this helps. You adapt a model to your domain, lock agents to enterprise rules, and measure performance across 13 eval frameworks before you ship. That’s the gap between a flashy proof-of-concept and something your CIO will actually bless.
Bold claim? Yep. But if you want AI that behaves, you need training where your data lives and guardrails that don’t break task success. Let’s unpack what Nova Forge and AgentCore actually bring—and how to use them without drowning in hype.
TLDR
- Nova Forge: fine-tune Nova LLMs on your own data.
- AgentCore Policy Engine: runtime boundaries plus user memory for context.
- Evaluations: 13 frameworks scoring safety, quality, and task success.
- Sweet spot: domain-heavy tasks where generic models hallucinate.
- Pricing and GitHub: details vary; watch AWS channels as docs land.
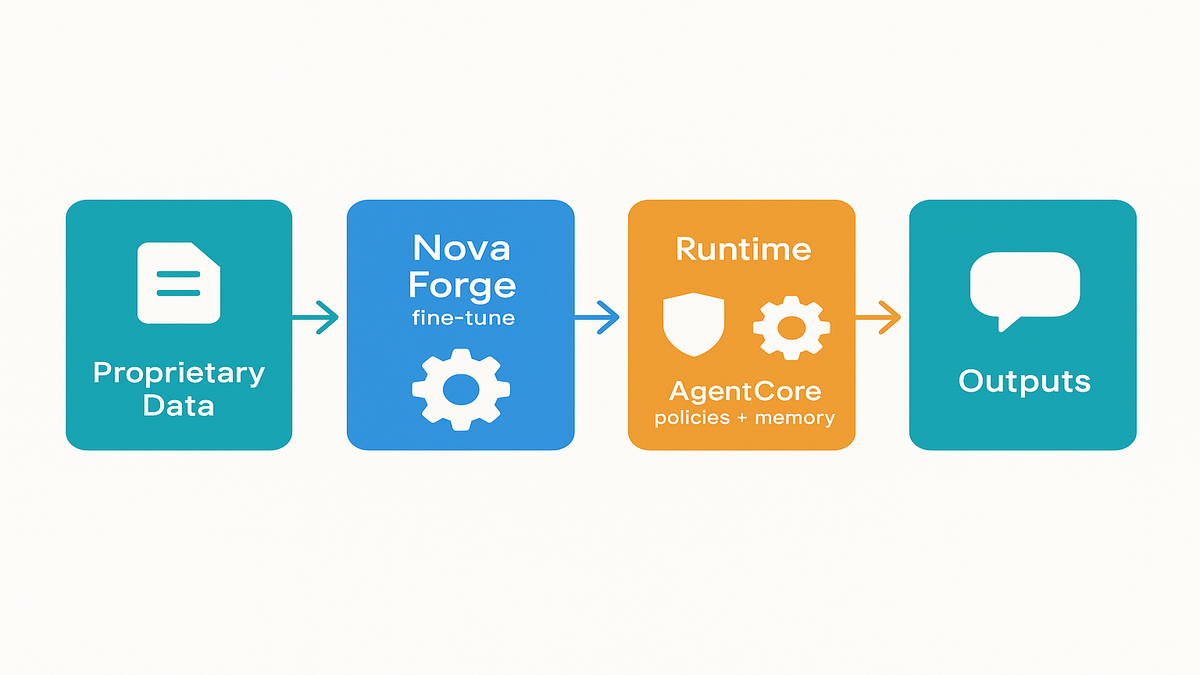
If the TL;DR is the appetizer, the main course is how these parts work together under load—when users show up with messy questions, half-finished info, and a talent for edge cases. The promise isn’t just smarter outputs; it’s predictable behavior you can audit, measure, and trust at scale.
Nova Forge in plain English
What you actually get
Nova Forge lets you fine-tune Nova LLMs on your own data. The value: move past prompt spaghetti and encode your domain—terms, formats, decisions—straight into weights. You cut prompt length, boost consistency, and make the model “think like your org.”
That means your model doesn’t just copy a style; it internalizes your definitions, workflows, and exceptions. Instead of stacking 40-shot prompts and praying, you train once on gold examples and benefit on every call. It’s the difference between sticky notes on a monitor and updating the actual playbook.
Why it matters
Generic LLMs guess. Your business can’t. With proper fine-tuning, you turn fuzzy reasoning into predictable workflows. Support macros reflect policy, product copy aligns to legal, and analytics summaries use metrics your CFO actually cares about. Short version: fewer hallucinations, more on-policy answers.
Fine-tuning also cuts token bloat. Shorter prompts, fewer system rules, lower latency, better cost control. Most teams don’t see how much spend comes from prompts that repeat the same rules. Bake those rules into the model once, and you save on every request after.
Where it fits
- Data stays in your environment while training jobs run on curated corpora.
- Pair Forge with retrieval for fresh facts and AgentCore for runtime constraints.
- Use Forge for core behaviors; keep prompts for per-request nuance.
A simple mental model: Forge is “who we are and how we work.” Retrieval is “what’s new today.” Policies are “what’s allowed right now.” Keep those roles clean, and the system stays stable as you scale.
A practical example
Picture onboarding analysts in fintech. You fine-tune Nova on internal KYC guides and ticket resolutions. Now the model recognizes your risk taxonomy out of the box. It formats SAR narratives in the house style and flags edge cases for human review. The goal isn’t zero human—it’s faster, safer first drafts that match your playbook.
Zoom out, and the same pattern works in healthcare intake, B2B sales ops, or manufacturing quality control. Anywhere you have repeatable logic plus strict guardrails, Forge locks in the logic so every answer starts closer to correct.
How to prep training data
- Start small and clean. High-quality beats high-volume. One bad example can teach the wrong move to thousands of queries.
- Label outcomes precisely. Good/better/best, final decision, and reason codes. Your labels teach the model what “success” means.
- Normalize formats. Consistent headers, fields, and style. Models learn quicker when patterns stay tight.
- Anonymize early. Replace PII with tokens like [NAME] and [ACCOUNT_ID] to prevent memorization.
- Keep a frozen validation set. If your validation drifts, you’ll ship regressions without noticing.
How to measure improvement
Track deltas against a baseline, not vibes:
- Accuracy versus gold answers on a held-out set.
- Edit distance from ideal responses, smaller is better.
- Time-to-resolution or cycles-to-first-correct.
- Refusal rate when an answer should be allowed.
- On-policy compliance rate, does it follow your rules?
If a fine-tune improves accuracy 10% but doubles refusals, that’s not a win. Look at compound outcomes: accuracy times completion times safety.
AgentCores Policy Engine decoded
What it binds
AgentCore’s Policy Engine constrains what agents can see, say, and do. Think allowlists and denylists, content filters, data access rules, and workflow limits. It layers in user memory so the agent remembers preferences and past context without re-asking.
Policies are your runtime truth. They translate risk rules into code the agent actually follows. What tools it can call, what fields it can fetch, who sees what, and when to escalate. The big win is consistency. Tuesday’s 3 a.m. chatbot behaves like Tuesday’s 3 p.m. human agent with a supervisor nearby.
The 13 evaluation frameworks
You can test agents across safety, quality, and reliability dimensions. Think toxicity, PII leakage, jailbreak resilience, hallucination rate, instruction-following, and task success. The point isn’t a vanity score; it’s a red, amber, or green gate for deployment.
Expect categories like adversarial robustness, harmful content detection, data exfiltration resistance, fairness and bias probes, tool-use correctness, and traceability. You don’t need to memorize the categories. You do need to run them before shipping and rerun them after any major change.
How memory changes the game
Memory shifts you from cold start answers to personalized continuity. Your support agent recalls the user’s last issue, preferred channels, and entitlements. Your research agent knows team definitions and past conclusions. Memory boosts CX and speed—but only if policies fence it in.
Two rules keep memory safe:
- Eligibility: define what can be remembered, like preferences or device type, and what cannot, like full card numbers or diagnosis details.
- Retention: set time windows and purge jobs. If you can’t explain why you kept it, you probably shouldn’t keep it.
Real world scenario
Retail returns chatbot. Policy says never expose full card numbers. Use store credits before refunds for flagged accounts, and escalate VIPs above $X. Memory recalls prior cases and loyalty tier. Evaluations prove it doesn’t leak PII under adversarial prompts. That’s how you scale without waking Legal at 2 a.m.
Add one more twist: throttled tool use. The agent can generate a refund only once per session without supervisor approval. If users push, it politely refuses and logs the attempt. That’s security with a smile, not a brick wall.
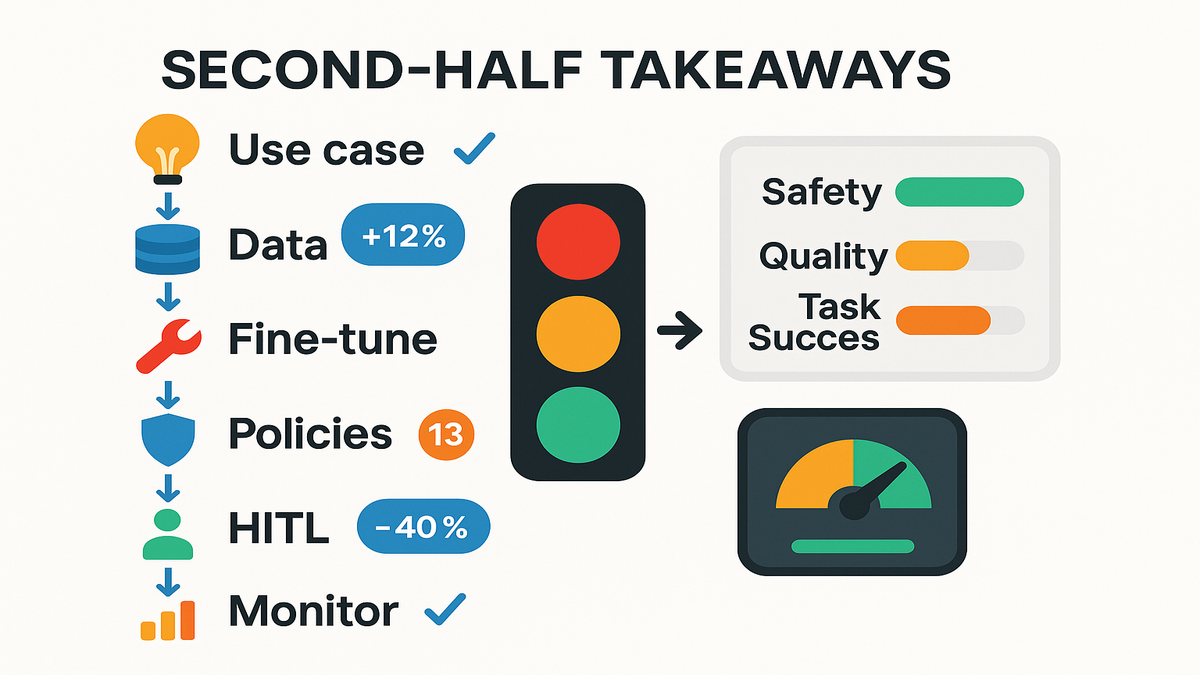
From POC to prod
Step 1 narrow use case
Choose tasks with repeatable structure. Support macros, sales proposals, compliance summaries, and internal Q&A. Success equals measurable throughput and quality gains.
Make it boring on purpose. Boring work has sharp edges and clear KPIs. You want undeniable wins. Fewer edits, faster responses, and fewer escalations.
Step 2 curate training data
- Deduplicate. Label outcomes. Remove contradictory examples.
- Strip sensitive fields or tokenize them.
- Keep a clean validation set to avoid overfitting.
Add a quick rubric for curators:
- Is this example like real traffic? Keep.
- Is it an edge case you want the model to handle? Keep, but label.
- Is it confusing, outdated, or off-policy? Fix it or drop it.
Step 3 fine tune Nova Forge
Start small. Establish a baseline with prompts only, then fine-tune on 1–5k high-quality examples. Track win-rate deltas. Accuracy, edit distance from gold answers, and time-to-resolution.
Keep an eye on drift. After the first fine-tune, add 100–200 new examples each sprint from human-in-the-loop feedback. Schedule monthly retrains so improvements stick, not just tribal knowledge.
Step 4 wrap AgentCore policies
Define guardrails before traffic hits. Content policy, tool-use limits, PII handling, and escalation paths. Turn on user memory for stickiness—and test that it never stores what it shouldn’t.
Document policies like API contracts:
- Inputs allowed, fields and formats.
- Outputs required, tone, disclaimers, and fields.
- Tools callable, and max calls per session.
- Escalation triggers and handoff details.
Step 5 run 13 evals
Push adversarial tests. Measure both safety and task completion. If a stricter filter drops completion by eight percent, tune it instead of disabling. Make tradeoffs explicit.
Run evals at three checkpoints:
- Baseline, prompt-only.
- Post-fine-tune, Nova Forge.
- Post-policy, AgentCore.
This isolates where gains and regressions come from. If policies tank completion, they might be overbroad. If fine-tuning boosts accuracy but increases hallucinations on unknowns, add refusal examples to training.
Step 6 human loop
Route ambiguous cases to humans. Capture corrections as new training data. Your loop should improve monthly, not ad hoc.
Target a healthy ratio. Automate the routine, escalate the unclear. If humans fix the same mistake more than twice, it belongs in the next fine-tune.
Step 7 monitor drift
Log refusals, jailbreak attempts, and off-policy actions. Treat eval regressions like failed unit tests—block deploys until green.
Dashboards that matter:
- Refusal rate by intent.
- PII redaction misses, this should be zero.
- Tool-call errors and retries.
- Content filter triggers by category.
- Average edits per human review.
Pricing GitHub evaluations
Nova Forge pricing
As of publication, detailed pricing didn’t show up in the re:Invent echoes. Expect the usual levers. Data processing, training time, checkpoints, and maybe storage or egress. Practical tip: start with a tight, high-signal dataset to get ROI before scaling. Always compare fine-tuning cost to prompt engineering plus retrieval alternatives.
Hidden costs to watch:
- Data labeling and review time, humans aren’t free.
- Evaluation runs before and after release.
- Re-training cadence as policies or products change.
- Model selection experiments you’ll later discard.
AgentCore pricing
Policy and evaluation features often meter by requests, eval runs, or agent-time. Budget for pre-deploy eval cycles plus ongoing spot-checks in production. Don’t skip evals to save cost—one policy failure in prod costs way more.
Line items leaders ask about:
- Per-request surcharge for policy checks.
- Memory storage and encryption at rest.
- Evaluation suite runs and report exports.
- Audit log retention by month or gigabytes.
nova forge agentcore github
Looking for code? Check for official samples under known AWS GitHub orgs like aws-samples and session repos linked from re:Invent recordings. If you don’t see a first-party repo yet, document your experiments. Keep your IaC for datasets, jobs, and policies versioned so you can swap in official modules later without refactors.
A simple structure that ages well:
- data/ for raw, curated, and validation.
- jobs/ for fine-tune configs and training specs.
- policies/ for YAML or JSON, with changelogs.
- evals/ for scenarios, prompts, and expected outcomes.
- infra/ for roles, storage, and CI/CD templates.
AgentCore evaluations in practice
Treat the 13 frameworks like a balanced scorecard. Run baseline, prompt-only. Then post-fine-tune with Nova Forge, and post-policy with AgentCore. Track deltas for safety and task success. A win looks like plus twelve percent resolution accuracy, minus forty percent PII risk, and stable or better CSAT. If safety spikes refusals, iterate on policy specificity—don’t just loosen thresholds.
Two operational tips:
- Keep an “adversarial bank” of tricky prompts. Every time a tester finds a hole, add it to the bank.
- Make evals part of CI/CD. New checkpoint or policy? No green, no ship.
What to watch next
Whats likely coming
- Tighter integration between Forge checkpoints and AgentCore evaluation dashboards.
- Pre-baked policy packs for regulated verticals.
- Evaluation presets mapped to internal risk ratings.
Also expect stronger support for audit trails. Per-response policy traces, decision rationales, and signed artifacts that make auditors smile, not squint.
Common gotchas
- Overfitting your tone, underfitting your logic. Teach reasoning, not only style.
- Memory creep. Define what’s eligible for memory, retention windows, and purge rules.
- Policy whiplash. Don’t toggle guardrails weekly. Use change windows and A/B tests to observe effects.
A bonus gotcha: ignoring tool error handling. If a tool fails, the agent should say so and escalate, not hallucinate success.
Security and compliance lens
Map policies to specific controls like PII redaction, data residency, and auditing. Log every blocked action and refusal reason. Auditors love a paper trail. Align evaluations with your model risk framework so AI fits your governance, not invents a new process.
Add the basics:
- Least-privilege roles for tools and data.
- Encryption at rest and in transit.
- Region pinning for data residency.
- Consent signals for memory features.
- Regular purge jobs and retention policies.
Bottom line
You’re buying two things. Better model behavior with Nova Forge and safer agent execution with AgentCore Policy Engine. Use both or risk a lopsided build. Smart model, dumb agent; or safe agent, useless outputs. The power move is the combo.
Halfway check
- Fine-tune with Nova Forge to encode your domain logic.
- Bind runtime behavior with AgentCore policies and user memory.
- Validate with 13 evaluation frameworks before any real traffic.
- Start small, measure deltas, and ship behind human-in-the-loop.
- Track safety and performance together; treat regressions like failed tests.
FAQ
1.
What is Nova Forge
It’s a service to fine-tune Nova LLMs on your data so the model reflects your terms, formats, and decision patterns. Use it when prompt-only approaches hit quality ceilings.
2.
AgentCore Policy Engine role
It constrains agent behavior with policies for access, content, and tool-use. It adds user memory for continuity and evaluates agents across 13 frameworks spanning safety, quality, and task success before you deploy.
3.
How 13 evaluation frameworks help
They provide measurable gates for shipping. You can quantify toxicity, PII leakage, jailbreak resilience, hallucination rate, instruction-following, and task-specific success. Launches stop being based on vibes.
4.
GitHub repo Nova Forge AgentCore
Availability can change. Look for official samples via AWS event pages or known GitHub orgs. If none are published yet, structure your experiments with versioned configs so adopting official modules later is painless.
5.
Pricing for Nova Forge AgentCore
Detailed pricing wasn’t provided in the re:Invent echoes referenced here. Expect usage-based components across training, evals, and requests. Start with small, high-signal pilots to validate ROI before scaling.
6.
Different from guardrails or RAG
Forge bakes domain behavior into the model itself. AgentCore enforces runtime policies and evaluations. RAG is great for freshness. But without fine-tuning and policies, you’ll still see inconsistency and safety gaps.
7.
Do I still need humans
Yes. Humans handle ambiguity, edge cases, and policy changes. Treat human feedback like fuel for the next fine-tune, not a permanent crutch.
8.
What metrics for execs
Show a one-page scorecard. Accuracy versus gold, completion rate, CSAT, average handle time, refusal rate, PII incidents with a goal of zero, and eval pass rates. Make safety and performance gains easy to read at a glance.
9.
Keep memory privacy compliant
Use opt-in, minimize what you store, encrypt it, and set retention windows. Purge on schedule and prove you purged with logs. If it’s sensitive and you don’t need it, don’t keep it.
10.
Run this without RAG
Yes, for stable, policy-heavy workflows. Add RAG when you need freshness like pricing, inventory, or docs. Forge handles behavior; RAG handles facts; policies keep it all safe.
Your 7 step launch plan
- Define one measurable use case with owner, KPIs, and SLAs.
- Curate 1–5k labeled, high-signal examples; hold out validation.
- Baseline with prompt-only and record metrics.
- Fine-tune via Nova Forge and compare deltas.
- Configure AgentCore policies and user memory; log refusals.
- Run the 13-framework eval suite; gate release on green.
- Roll out with human-in-the-loop and weekly drift reviews.
You want AI your ops team actually trusts. Nova Forge gets you a model that speaks your language. AgentCore Policy Engine makes sure it follows the rules when it matters. Put them together, and you move from demo weekends to durable production.
Pro tip: Most AI failures aren’t model problems—they’re governance problems dressed up as creativity.
References
- AWS re:Invent (official)
- AWS Events YouTube (keynotes/sessions)
- Guardrails for Amazon Bedrock (docs)
- Model evaluation in Amazon Bedrock (docs)
- Agents for Amazon Bedrock (docs)
- NIST AI Risk Management Framework 1.0
- OWASP Top 10 for Large Language Model Applications
- MITRE ATLAS (Adversarial Threat Landscape for AI)
- GDPR principles (data minimization, storage limitation)
- U.S. HHS HIPAA Privacy Rule overview