

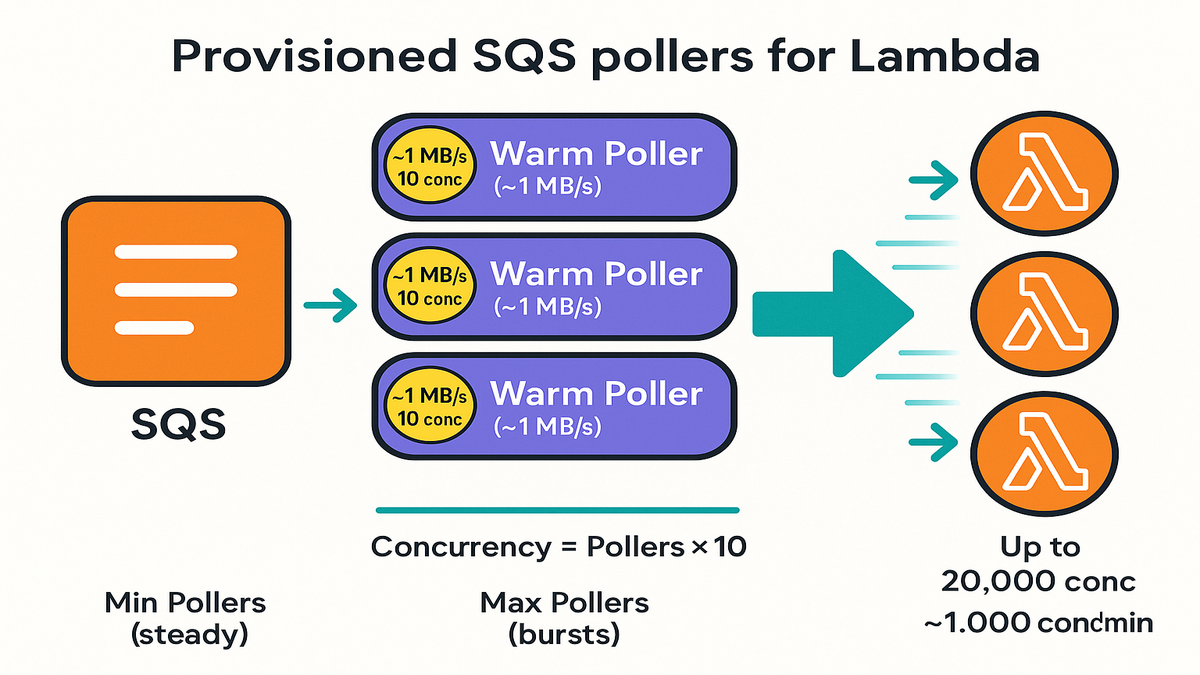
You can cut SQS-triggered Lambda latency by turning on provisioned mode for the SQS event source mapping. It keeps dedicated pollers warm, so scale-up is about 3x faster. It supports up to 20,000 concurrent invokes. Each poller can push about 1 MB/s and up to 10 concurrent invokes.
If your Lambda wakes up slow or queue spikes shake your p95, this helps. Provisioned mode keeps a pool of pollers hot, ready to grab messages right away. No waiting for the normal scale-up logic to wake and ramp.
Think of it like preheating an oven. Cold starts aren’t only about your Lambda code. SQS polling has its own warm-up and ramp. Provisioned mode shortens that ramp, cuts jitter, and gives you knobs for cost and speed.
If you run sharp bursts—adtech auctions, market data, personalization, or matchmaking—this is great. Provisioned pollers give your system a head start without drama. You set minimum pollers for steady state and maximum for burst ceilings. Your Lambdas stay fed, latency stays boring, and on-call gets their evening back.
TL;DR
- Dedicated pollers stay warm; faster scaling and steadier latency
- Up to 20,000 concurrent invokes; scale rate up to ~1,000 conc/min
- Control cost and performance with min/max pollers you set
- Per poller: up to 1 MB/s throughput and 10 concurrent invokes
- Great for finance, gaming, ecommerce, IoT, adtech, observability
If you're shipping this for adtech workloads, check out Requery. It does high-velocity event querying and measurement next to your Lambda + SQS pipelines.
Provisioned mode doesn’t change how you build; it changes how fast you react. You still write the same handler, use the same queue, same IAM roles. What you gain is control. You set the poller floor and ceiling, and Lambda keeps them hot. When messages show up, invokes begin right away instead of waiting to scale. That’s why p95s get steadier in load tests.
What provisioned pollers do
SQS event source mappings bridge your queue and your Lambda function. By default, they scale reactively. Messages arrive, AWS adds pollers, and your concurrency ramps up. That works, but there’s a small delay while sizing happens.
Provisioned mode flips that. You configure a minimum number of pollers that stay alive even idle. These pollers long-poll SQS nonstop and hand batches to Lambda. Invocations keep flowing without the warm-up gap. When traffic spikes, the service scales faster up to your max pollers and regional quotas.
Key ideas
- Dedicated pollers are always on, so no warm-up needed. First message moves fast. The next hundred do too.
- Each poller can drive about 10 concurrent invokes and roughly 1 MB/s of data. This depends on message size, batch size, window, and function duration.
- You choose min pollers (your latency floor and base cost) and max pollers (your burst safety ceiling). This is the cost vs p95/p99 trade.
- All the usual SQS + Lambda rules still apply: visibility timeouts, partial batch responses, DLQs, IAM, and CloudWatch metrics.
If you already tune batch size and window, provisioned mode multiplies those gains. Smaller windows lower latency. Bigger windows boost throughput. Provisioned pollers just make scaling faster and more predictable when queues get spicy.
How to size
- Concurrency ~= pollers * 10
- Pick min pollers for steady state; max pollers for bursts
- Ensure Lambda account concurrency quotas match your targets
Deep dive sizing examples
Start by choosing your target p95 latency and expected burst size. Then back into pollers using your function’s average duration and message size.
Example A small messages
- Messages: ~5 KB each, standard queue
- Function duration: 100 ms avg
- Desired burst concurrency: 2,000
- Pollers needed: 2,000 / 10 = ~200 max pollers
- If you want a steady p95 during micro-bursts, set min pollers to 40–60. That keeps 400–600 concurrent invokes ready now, and it will scale toward 2,000 as load rises.
Example B longer work
- Messages: ~100 KB each
- Function duration: 1 second
- Desired steady throughput: ~500 messages/sec
- Each poller can drive roughly 10 concurrent invokes. With 1-second duration, that’s ~10 msgs/sec/poller in steady state.
- Pollers needed for steady state: 500 / 10 = 50 min pollers
- For bursts to 1,500 msgs/sec, set max pollers to ~150
Example C FIFO ordering
- With FIFO and message groups, parallelism is gated by the number of active groups.
- If you need 1,000 concurrent invokes, you need at least 1,000 active groups. Provisioned pollers ramp faster, but ordering still rules. Plan pollers around active groups, not only raw concurrency.
Pro tip: right-size batch size before chasing pollers. Bigger batches add efficiency and reduce cost, but can raise perceived latency. If you want p95 under 200 ms, keep the window tight and use more pollers. If you want throughput at lowest cost, widen the window and maybe lower pollers.
Operational tips
- Tune batch size/window (small window for low latency)
- Visibility timeout > worst-case processing time (with headroom)
- Enable partial batch responses; send failures to an SQS DLQ
Tuning that actually moves p95p99
Batch size and MaxBatchingWindowInSeconds
- Small window = faster first-byte-to-exec time. Try 0–1s for low-latency paths.
- Larger window = better efficiency and fewer invokes per N messages. Consider 2–10s for heavy throughput or cost control.
- Calibrate with your function’s average duration. If it runs in 50–150 ms, a 0–1s window keeps queues fresh without starving throughput.
Visibility timeout
- Set it greater than worst-case processing time with a safe buffer. This avoids duplicates from long tails or blips.
- If downstream calls sometimes spike, keep a generous multiplier. Use 2x–6x your 99th percentile duration, based on idempotency.
- Watch ApproximateAgeOfOldestMessage and adjust if you see reprocessing or odd inflight churn.
Partial batch responses
- This is a must. When one record fails, only return the failed ones. The rest move forward, keeping the line moving.
- Combine with a Dead-Letter Queue so poison messages don’t clog retries.
- Build idempotency into handlers to safely retry only failed items.
Other knobs worth checking
- Memory size and CPU: CPU scales with memory in Lambda. If CPU-bound, bump memory to cut duration and boost per-poller throughput.
- Cold starts: Provisioned Concurrency helps if init time dominates. Provisioned pollers don’t replace it; they complement it.
- Timeouts: Keep Lambda timeouts below SQS visibility timeout, with room for retries.
When to use
- Latency-sensitive, bursty workloads (market data, matchmaking, personalization, fraud checks)

Where provisioned pollers shine
Finance and market data
- Price updates, order routing, and position checks hit in bursts at open/close. Provisioned pollers reduce jitter, so checks feel instant even during spikes.
Gaming and matchmaking
- Player joins and leaves create spiky demand. You want matching to start right away. Provisioned pollers keep response times flat during surges.
Ecommerce and personalization
- Flash sales and drops crush queues in minutes. Faster scale-up keeps recs, cart checks, and promos from lagging during surges.
Fraud detection and risk scoring
- Low latency matters or people bounce. Keep windows tight, use more pollers, and feed scoring logic without delay.
IoT and observability
- Device bursts and telemetry spikes need steady drain rates. Provisioned pollers smooth the ramp so you stay near real time.
Rollout checklist
- Benchmark p95 time and choose a target
- Set min/max pollers
- Configure batch size/window and visibility timeout
- Enable partial batch responses and DLQ
- Load test and monitor concurrency, queue depth, DLQ inflow, p95/p99
How to run the playbook
1 Baseline your current setup
- Measure p50/p95/p99, function duration, errors, and SQS ApproximateAgeOfOldestMessage. Note latency during a 5–10x synthetic burst.
2 Pick targets
- Choose a realistic p95 target, like 150–250 ms end-to-end. Decide your max burst and acceptable drain time. Example: clear 1M messages in 10 minutes.
3 Set min max pollers
- Start with min pollers to cover steady state plus 20–30% headroom. Set max pollers for your burst goal without hitting account limits.
4 Tune batch size window
- If latency is king, keep window at 0–1s and use modest batches. If cost is king, widen the window and let bigger batches win.
5 Configure safety rails
- Visibility timeout: 2–6x worst-case. DLQ attached. Partial batch responses on. Idempotency keys in payloads or storage.
6 Load test iterate
- Drive real traffic patterns: message size, fan-out, payload mix. Watch ConcurrentExecutions, ApproximateNumberOfMessagesVisible, OldestMessageAge, Errors, and DLQ inflow. Adjust pollers in small steps.
Docs
- Using AWS Lambda with Amazon SQS
- Event source mappings
- Lambda concurrency
- SQS visibility timeout
- SQS dead-letter queues
- Partial batch responses
For real-world wins in streaming and adtech, check our Case Studies.
Cost and quota guardrails
- Lambda account concurrency: Make sure your Regional limit covers max pollers * 10. If not, request an increase before launch.
- Scaling rate: Even with faster ramp, you’re bound by regional quotas and rules. Keep expectations realistic in runbooks and alarms.
- DLQ volume: Faster pipelines move failures faster too. During bad deploys, DLQ may spike—alert on DLQ inflow and size.
- Storage and downstream capacity: Faster delivery shifts load downstream. Check that databases, caches, and APIs can take the extra heat.
Patterns for provisioned pollers
- Idempotent processing: Generate a stable key, like orderid or eventid. Use it to guard against duplicates.
- Strangler deploys: Turn on provisioned pollers in canary first. Then ramp min/max in prod during a quiet window.
- Backpressure via queue design: If downstream is fragile, split queues by workload or priority. Provision pollers per queue.
- FIFO and message groups: For strict ordering, make message groups match real parallelism, like customer_id or region.
Observability what to watch
- SQS ApproximateNumberOfMessagesVisible: Your queue depth. If it grows faster than it drains, increase pollers or shrink the window.
- SQS ApproximateAgeOfOldestMessage: If this rises during normal load, you’re under-provisioned or downstream is choking.
- Lambda ConcurrentExecutions: Confirms you hit the expected concurrency from pollers.
- Lambda Duration, Errors, and Throttles: Duration creep raises your visibility timeout needs. Throttles may mean quotas.
- DLQ inflow rates and sample records: Early sign a deploy broke something or a dependency is flaky.
FAQ quick answers
- Does provisioned mode change my code?
- No. It changes how the event source mapping polls and scales. Your handler and IAM stay the same.
- Is this the same as Provisioned Concurrency for Lambda?
- Different layers. Provisioned Concurrency warms execution environments. Provisioned pollers warm the SQS polling layer. Use both for the lowest latency.
- Does it work with FIFO queues?
- Yes, but ordering still applies. Parallelism depends on the number of active message groups. Provisioned pollers ramp faster within those rules.
- What batch size/window should I start with?
- For latency-sensitive paths, use a small window (0–1s) and moderate batches. For throughput, try a larger window and measure cost per 1,000 messages.
- How do I avoid reprocessing messages?
- Set visibility timeout > worst-case time, enable partial batch responses, and make handlers idempotent. Attach a DLQ for the stubborn ones.
- What if my messages are large?
- Watch the ~1 MB/s per poller guidance as a planning rule. Test with your real payload mix. Larger messages often like more memory and a slightly bigger window.
- Can I tune per environment?
- Yes. Different queues can have different mapping settings. Use lower min pollers in dev and staging, and scale in prod.
Example roll forward plan
- Week 1: Enable partial batch responses and set DLQs in all envs. Build CloudWatch dashboards for SQS and Lambda metrics. Add alarms on queue age and DLQ inflow.
- Week 2: Turn on provisioned mode in staging. Pick min/max pollers at ~50% of prod steady state. Run synthetic bursts. Validate p95 hits target.
- Week 3: Enable in prod with conservative min pollers and aggressive max. Run an off-peak canary, 5–10% for an hour. Check downstream saturation.
- Week 4: Raise min pollers to meet p95 goals during the busiest hour. Document rollback: set min pollers to 0 and cut max by half if alarms fire.
Real world pitfalls to avoid
- Too-short visibility timeout: A few slow downstream calls and you’ll see duplicates. Give headroom.
- Forgetting quotas: Pollers * 10 adds up fast. Check Lambda regional concurrency and reserved concurrency.
- Over-batching on latency paths: Big batches help cost but add wait time. Keep the window small if user latency matters.
- Ignoring DLQs: Poison messages can hammer retries. DLQ plus partial batch responses keeps pipelines healthy.
- Not load testing with real payloads: Include big messages, slow third-party calls, and error cases in tests.
If you like boring graphs and happy on-call, this is a strong move. Provisioned pollers for SQS + Lambda trade a little fixed cost for a lot more predictability. Start with small min pollers, keep batch windows tight, and scale only when your metrics ask.
References
- AWS Lambda: Using Amazon SQS as an event source
- AWS Lambda: Event source mappings
- AWS Lambda: Managing Lambda concurrency
- Amazon SQS: Visibility timeout
- Amazon SQS: Dead-letter queues
- AWS Lambda with SQS: Partial batch responses (reporting batch item failures)
- Amazon SQS: Monitoring with Amazon CloudWatch
- Amazon SQS: FIFO queues and message groups