

You didn’t fly to Vegas, but you still want the signal. Here’s a fast, no-fluff re:Invent 2025 recap you can use to make real decisions this week.
The short version: agentic AI stopped being a slide and became a product pattern. Multimodal models moved from “cool demo” to “default input.” Zero‑ETL isn’t a buzzword—it’s a blueprint. And AWS is turning sustainable compute from virtue into a cost edge.
If your teams keep asking, “What should we build next?”—this is your cheat code.
If you skipped the neon badges and hallway buzz, you didn’t miss the plot. The theme was simple: ship real systems faster, safer, and cheaper—especially for gen AI. Expect less hand‑waving, more templates and guardrails you can use without rewriting your stack.
Think building blocks, not moonshots. Bedrock Agents give you agent basics. Multimodal models turn screenshots, PDFs, and audio into context. Neuron + Inferentia/Trainium unlock better inference economics. Zero‑ETL connects your ops data to analytics. And sustainable compute trims both cost and carbon.
Bottom line: you can move from demo to dependable. Start small, measure hard, and let wins compound.
TLDR
- Agentic AI is moving into production via Amazon Bedrock Agents—tool use, planning, and guardrails built in.
- Multimodal FMs are table stakes for search, support, and analytics; Bedrock’s catalog keeps growing.
- AWS Neuron + Inferentia/Trainium = cheaper, faster gen AI inference at scale.
- Zero‑ETL cuts glue work and unlocks fresher analytics for product and ops.
- Sustainable computing is now a performance play: Graviton + efficiency targets push cost and carbon down.
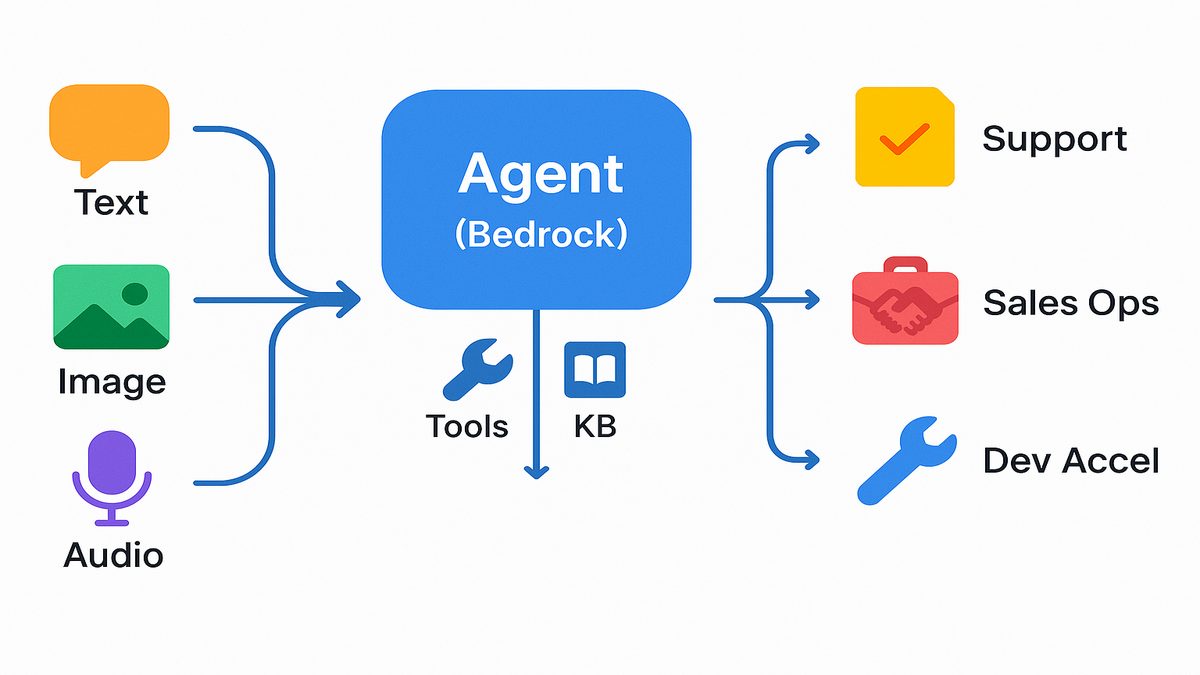
Agentic AI That Ships
Why this matters now
Agentic AI isn’t just “chat with a PDF.” It’s models that plan, call tools, read from knowledge bases, and do multi‑step work—reliably. That’s the gap between demos and revenue.
AWS leaned in with Agents for Amazon Bedrock: orchestration basics (planning, tool use), retrieval, and guardrails you can govern from day one. As AWS says, “Agents for Amazon Bedrock help you build generative AI applications that can complete complex tasks for your users.”
What this means tactically: you can define tools like "createticket", "fetchinvoice", and "apply_discount", wire a knowledge base, then let the agent plan multi‑step flows. It’s not about a better prompt; it’s about reliable execution with logs, traces, and policies.
Capabilities to prioritize first
- Tool reliability: deterministic schemas, strict input validation, and clear error paths.
- Retrieval discipline: narrow, high‑quality corpora; pick curated knowledge over dumping your whole wiki.
- Guardrails: safety filters, PII handling, and allow/block lists tuned to your domain.
- Observability: structured logs for each tool call and step; trace IDs tied to user actions.
What to build first
- Customer support that resolves tickets end to end by calling internal APIs.
- Sales ops agents that read CRM context, draft outreach, log tasks, and book meetings.
- Dev acceleration agents that summarize logs, open JIRA issues, and propose fixes.
Start with one high‑value playbook, like “refund request” or “new hire setup.” Define inputs, outputs, and success signs: resolution rate, time to resolution, and human takeover rate. Limit scope to two or three tools so you can harden reliability fast.
Guardrails evals and governance
Bedrock plugs into knowledge bases, model evals, and policy controls—key for finance, health, or public sector. Start narrow with high‑ROI playbooks, then widen scope.
Expert note: “Start with tool reliability before model cleverness—instrument every API call and add graceful fallbacks.” That’s the difference between a magical demo and a 3 a.m. pager.
Practical governance pattern: define a policy layer that maps user roles to tool rights and data scopes. Log every action with reason codes, and run a weekly eval suite (golden prompts plus expected tool sequences). Treat agents like microservices: SLOs, runbooks, and rollback plans.
Metrics that matter:
- Success rate per playbook (no human handoff needed)
- Tool call error rate and retry spread
- Average steps per task and step‑level latency
- Hallucination or irrelevant‑action rate in evals
Reference: See Agents for Amazon Bedrock.
Multimodal Is the Default
What changed
Your users don’t only type. They paste screenshots, upload docs, and leave voice notes. Multimodal models—text, image, audio, sometimes video—turn that messy edge into clean context. On Bedrock, you can pick from a model catalog (Anthropic, Meta, Mistral, Amazon Titan) and swap as needs change.
Amazon’s stance is clear: “Amazon Bedrock is the easiest way to build and scale generative AI applications with foundation models.” Translation: managed endpoints, eval tools, retrieval, and controls in one place.
To win here, nail ingestion and normalization. Add OCR for images with text. Pull tables as structured data. Store doc chunks with metadata like source, page, version, and permissions. Treat metadata as fuel for relevance and audits.
Practical wins
- Support: users upload screenshots; the model extracts error codes, checks the KB, proposes steps.
- Search: multimodal RAG turns PDFs, images, and tables into answers—not links.
- Analytics: summarize dashboards, annotate charts, and generate “explain like I’m CFO” recaps.
Turn those into measurable outcomes:
- First‑response resolution lift vs. text‑only flows
- Time‑on‑task drop for support agents
- Search NPS/feedback gains and lower “no result” rates
- Exec adoption rates for CFO‑style summaries
Model choice lock in avoidance
Keep your prompts and eval data portable. Bedrock’s model routing helps, but you still want benchmark harnesses and A/B tests in CI for models, not just code.
Pro tip: if you’re new to multimodal, start with one high‑friction workflow, like image‑to‑troubleshoot. Measure first‑response resolution lift vs. your text‑only baseline. Then expand.
Costs and control
- Use smaller, task‑specific models for extraction and a larger model for synthesis.
- Cache embeddings and intermediate parses where allowed.
- Set max token and image size rules; reject low‑quality uploads early.
- Keep a fallback model path if your primary hits throttles or a regression.
Reference: Explore the Amazon Bedrock overview.

Cheaper Faster Inference
The money slide
Inference, not training, is where your budget goes to die. AWS Neuron—the SDK for Inferentia and Trainium—lets you compile and run models with high throughput and low latency on purpose‑built chips. If you’re scaling assistants, RAG, or batch gens, this is where unit economics move.
AWS puts it simply: “AWS Neuron is the SDK for AWS Inferentia and AWS Trainium.” The stack plugs into PyTorch or TensorFlow, supports compilation, graph tweaks, and profiling. You keep your model code; Neuron does the silicon‑specific magic.
When to switch
- You’ve stabilized prompts and contexts; cost per 1k tokens is the constraint.
- P95 latency and concurrency are spiky; CPUs/GPUs are overkill or underused.
- You need steady capacity without the GPU scramble.
Think in workloads:
- Interactive assistants: prioritize tail latency and streaming response quality.
- Batch summarization or scoring: prioritize throughput and cost per job.
- RAG‑heavy flows: profile non‑model steps first—embeddings, retrieval, tokenization.
Migration path
- Start with a shadow stage: route a slice of traffic to Inferentia endpoints. Compare outputs and latencies.
- Use Neuron tools for kernel fusion and mixed‑precision tweaks.
- Lock SLOs first, then optimize for price and performance.
Engineer tip: “Profile your tokenizer and RAG steps—half your latency isn’t the model.”
Extra knobs to turn:
- Batching where supported, with strict timeouts to protect tail latency.
- Token streaming for perceived latency wins in chat UIs.
- Prompt templates that cut token bloat; shorter system prompts save money.
- Cache permissioned retrieval results when allowed.
References: What is AWS Neuron? and AWS Inferentia/Trainium.
Sustainable Compute Edge
Not just ESG
Sustainability is now a performance and cost story. Efficient chips (hello, Graviton), right‑sized instances, and smarter data movement lower your bill and your footprint. Big picture: data centers’ energy demand is rising; the bar for efficiency keeps moving.
IEA notes data centers and data transmission networks use a meaningful share of global electricity and are growing fast. Translation: your CFO and sustainability team are both watching.
Amazon’s public goals are clear: “Amazon is committed to powering its operations with 100% renewable energy by 2025,” and “AWS is committed to being water positive by 2030.” On silicon, AWS says Graviton can deliver better price/perf and energy efficiency for many workloads.
What to do this quarter
- Move CPU‑bound services to Graviton‑backed instances; measure price and perf deltas.
- Use rightsizing and workload‑aware autoscaling; kill zombie fleets.
- Co‑locate AI retrieval with compute to cut data egress.
Add a simple playbook:
- Baseline: capture current cost, CPU/mem, and P95 latency per service.
- Pilot: build multi‑arch containers, run canaries on Graviton, compare perf.
- Expand: migrate the 20% of services that drive 80% of CPU hours.
- Report: share monthly efficiency gains and reinvest savings.
Think of it like tech debt: operational waste compounds. Efficiency is a feature customers feel—faster apps, lower costs, smaller footprint.
References: IEA on data centers, Amazon renewable energy commitment, AWS water positive by 2030.
Zero ETL System Design
The idea
Data freshness beats dashboard glitter. Zero‑ETL links operational stores to analytics engines without bespoke pipelines. Less glue code, fewer cron jobs, more real‑time decisions.
AWS rolled out zero‑ETL integrations across services like Amazon Aurora and Amazon Redshift, with added connectors for DynamoDB. In AWS’s words, these integrations “eliminate the need to build and manage ETL pipelines,” so you can focus on queries, not plumbing.
Under the hood, think change streams feeding managed ingestion into Redshift, with schema mapping and IAM‑based access. You still need contracts and data quality checks. Zero‑ETL doesn’t mean “no modeling.” It means “first‑class plumbing.”
Where this lands
- Product analytics: stream changes from OLTP into Redshift for feature usage and cohorts.
- FinOps: revenue and cost data land in one place for daily margin snapshots.
- Ops: near real‑time anomaly detection using simpler ingestion paths.
Design guardrails
- Agree on canonical schemas and data contracts early.
- Keep PII boundaries explicit; encrypt and token‑gate access.
- Bake lineage and data quality checks into the flow.
Make it safe and useful:
- Use role‑based access control and row‑level security on analytics.
- Set freshness SLOs, like 5–10 minutes, and alert when drift exceeds targets.
- Track the cost of queries from real‑time dashboards; cap and tune.
- Favor materialized views for hot aggregates; schedule refresh windows.
If you do one thing: pilot Aurora→Redshift zero‑ETL for one service. Wire Lookout or QuickSight on top, and measure cycle‑time collapse, from batch day to intraday.
If you’re building measurement and activation on Amazon Marketing Cloud, you can speed up pipelines, governance, and reporting with AMC Cloud.
References: Aurora zero‑ETL to Redshift GA, DynamoDB zero‑ETL to Redshift (preview).
Quick Pulse Check
- Agentic AI is production‑ready on Bedrock—start with narrow, high‑ROI workflows.
- Multimodal is default UX—images, docs, and text together beat text only.
- Inference is the cost center—Neuron + Inferentia/Trainium flips unit economics.
- Sustainable compute is a performance win—optimize instances, placement, and movement.
- Zero‑ETL cuts glue work—fresh data without nightly breaks makes teams faster.
Translate that into one principle: pick one workflow, prove it end to end, then clone the pattern.
Team FAQs
1 biggest aws reinvent 2025
Agentic AI via Amazon Bedrock Agents, momentum on multimodal foundation models in Bedrock, efficiency gains with AWS Neuron on Inferentia/Trainium for inference, and practical zero‑ETL that links operational and analytics stores. These are things you can adopt this quarter.
2 watch aws reinvent replays
Check the AWS Events YouTube channel for keynotes and sessions on‑demand. You can also browse the official re:Invent site for curated sessions and paths.
3 Bedrock Agents vs DIY
You could stitch prompts, tools, and policies yourself. But Bedrock Agents bundle planning, tool use, retrieval, and guardrails—plus AWS security and governance. It’s faster to stand up, simpler to audit, and easier to scale across teams.
4 inference on Inferentia Trainium
Once your model and prompts stabilize and you’re chasing cost and latency. Start with shadow traffic, keep outputs aligned, then scale. Neuron’s profiling and compilation help you squeeze throughput without rewrites.
5 is zero ETL realistic
Not everywhere. For common OLTP→analytics flows like Aurora→Redshift, zero‑ETL removes tons of brittle pipelines. Use it where schemas are stable and freshness matters. Keep bespoke ETL where heavy transforms are needed.
6 map to sustainability goals
Graviton adoption, right‑sizing, and less data movement cut costs and carbon. Pair that with renewable‑energy‑backed regions and water‑positive goals to meet performance and compliance.
7 keep data private Bedrock
Scope access with IAM. Use private networking where supported. Encrypt data in transit and at rest, and avoid logging sensitive prompts or outputs. Review Bedrock data privacy guidance and set guardrails for PII handling.
8 pick foundation model Bedrock
Start from the task and limits: do you need reasoning, extraction, or summarization? Check latency, cost per 1k tokens, input modes, and safety features. Run a small benchmark with real prompts and measure quality vs. price.
9 estimate costs before ship
Map the request path: tokens in and out, retrieval calls, embeddings, and concurrency. Multiply by expected traffic, then run a 1–2% canary to verify. Use the AWS Pricing Calculator and pricing pages to sanity‑check.
10 compliance
Confirm service compliance posture. Keep data in approved regions and enforce least‑privilege access. Centralize logs and audits, and review findings often with security and legal.
Ship This Week
1) Pick one agentic workflow, support or ops. Define tools and guardrails. 2) Prototype with Agents for Amazon Bedrock. Add retrieval from a governed knowledge base. 3) Stand up a zero‑ETL pilot, Aurora→Redshift. Wire a minimal dashboard. 4) Benchmark inference on your stack vs. Inferentia via AWS Neuron; shadow 10% of traffic. 5) Migrate two CPU‑bound services to Graviton; measure price/perf and set a rollback plan. 6) Add evals: golden prompts, toxicity filters, and output consistency checks. 7) Write a one‑pager with results, costs, and a 30‑day roadmap. Share, iterate, expand.
Make each step shippable:
- Agent definition of done: target resolution rate, guardrail policy, and a runbook.
- Zero‑ETL pilot: freshness SLO, lineage report, and one KPI chart everyone can read.
- Inference benchmark: side‑by‑side latency and cost curves at P50/P95; a decision memo.
- Graviton migration: perf deltas and a rollback plan validated in staging.
- Evals: weekly run, tracked over time, with failure analysis and fixes.
You don’t need a 12‑month roadmap to gain from re:Invent 2025. You need one high‑ROI agent, one zero‑ETL pipe, and one inference win. Stack those, and you’ll feel compounding effects: faster cycles, lower costs, happier users. Do the unglamorous bits—instrumentation, guardrails, data contracts—and your AI strategy becomes an operational edge your rivals can’t screenshot.
Want real‑world examples of these patterns in action? Explore our Case Studies.
References
- Agents for Amazon Bedrock (documentation)
- Amazon Bedrock overview and model catalog
- What is AWS Neuron? (documentation)
- AWS Inferentia and Trainium overview
- IEA: Data centres and data transmission networks
- Amazon renewable energy commitment
- AWS water positive by 2030
- Amazon Aurora zero‑ETL integration with Amazon Redshift (GA)
- Amazon DynamoDB zero‑ETL integration with Amazon Redshift (preview)
- AWS Events YouTube (replays)
- Guardrails for Amazon Bedrock
- Knowledge Bases for Amazon Bedrock
- Model Evaluation on Amazon Bedrock
- Amazon Bedrock data privacy
- AWS Graviton overview
- AWS Well‑Architected Framework – Sustainability Pillar
- Amazon Redshift Security Overview
- Amazon Bedrock and VPC endpoints
- Amazon QuickSight
- Amazon Lookout for Metrics
- AWS Pricing Calculator
In tech, the fastest compounding isn’t features—it’s feedback loops. Zero‑ETL feeds your models; agentic AI closes the loop.