

If you blinked, you missed it. Amazon Bedrock now hosts 100+ foundation models. Agents got smarter fast, too. AWS also lined up a global tour of Community Days and Summits. Translation: the cloud environment is shifting in real time. You either ride the current or get swept.
Think of this as your ecosystem updates news today. Practical, fast, and focused on next steps. Not climate environmental news today, to be clear. But it is your latest environmental news 2026 for tech. Who’s launching what, where to plug in, and which moves compound.
You’re getting the playbook. Which events to hit, how to use new AI blocks, and why data architecture matters now. Yes, DynamoDB global tables with multi-account replication included. If you like ecology articles for students that map food chains, this fits. It’s the cloud version—services, dependencies, and where value flows.
Hot take: In ecosystems—biological or cloud—the fastest adapters win. Everyone else becomes someone else’s case study.
Quick orientation before we dive in. Think tiny bets, fast loops, and clear metrics. You don’t need a 3‑month offsite to move. You need two events, one thin-slice feature, and one plan to measure. Keep it scrappy and very specific.
TLDR
- AWS Community Days roll across cities; AWS Summits 2026 are free and AI-heavy.
- Amazon Bedrock adds more open-weight models; agents mature for real workflows.
- Compute gets a boost, like new EC2 families; DynamoDB expands global options.
- GovCloud growth means compliant-by-default builds don’t have to be slow now.
- Your move: pick 2–3 events, ship one AI feature, and harden data strategy.
If you read nothing else, read this. Show up where builders are, test two models. One managed and one open-weight. Also, get your data closer to your users. That combo gives speed, control, and lower latency. The boring stuff that wins.
Use this as your short-term map. Treat each section like a sprint card. One decision, one test, one metric. Small moves, stacked weekly, beat giant bets that never ship.
Where the Action Is
Whats happening now
You’ve got a packed calendar, seriously. AWS Community Days are planned for Ahmedabad, Tokyo (JAWS Days), Chennai, Slovakia, and Pune. Then come AWS Summits 2026 in Paris, London, and Bengaluru. They’re free, high-signal, and focused on AI, data, and cloud-scale ops. If you waited for a low-friction level up, this is it.
Community Days are built by users for users. Expect workshops, labs, and talks from builders who’ve shipped. Summits are the official deep-dives. You can preview roadmaps, hit chalk talks, and leave with deployable patterns.
Here’s how to squeeze real ROI. Show up with one problem to solve, like cost or latency. Or compliance, that’s fair. Bring a shortlist of sessions and three people you want to meet. If you can’t travel, many talks go online anyway. Follow event pages, the AWS Events hub, and community recaps.
Why you should care
Events aren’t swag runs. They’re force multipliers for teams who plan. Line up customer discovery, partner intros, and SA office hours in one sprint. If you track ecosystem news, these are field studies. They’re live, current, and shaped by what’s working.
Block 48 hours after the event for follow-ups. Turn notes into tasks, book debriefs, and set a 14‑day ship window. Events only matter if they change what ships next.
A first hand style example
You’re a startup in Pune. You attend Community Day and catch a hallway chat with a fintech architect. You learn how they cut inference costs by moving to an open-weight model on Bedrock. Two weeks later, you implement it and cut your bill 28%. That’s not theory. That’s event compounding.
Add the kicker. You publish a tiny write-up and tag the speakers. You get two inbound partner intros. Knowledge turns into pipeline when you share the win.
Pro tips inside the room
- Take one problem to solve and ask it in three sessions.
- Book builder sessions early; hands-on labs fill up fast.
- Leave with one “ship in 14 days” commitment.
Pro tips outside the room
- Build a one-pager: problem, current numbers, and target numbers. Hand it around.
- Pre-commit to one office hours slot per day. Live debugging beats guesswork.
- Join the event Slack or Discord. Quick follow-ups and code snippets live there.
Sample day plan Summit edition
- 9:00–9:30: Keynote. Note three takeaways tied to your roadmap.
- 10:00–11:00: Chalk talk on agents and guardrails.
- 11:30–12:30: Lab. RAG with Bedrock and retrieval.
- 13:30–14:00: Booth chat with a partner on observability.
- 14:30–15:00: SA office hours on your data architecture.
- 16:00–16:30: Networking break. Book two follow-up calls.
AI Under the Hood
What just landed
Amazon Bedrock now hosts 100+ foundation models. The roster of open-weight options keeps growing. You can deploy with more control when you need it. Agents in Bedrock are maturing as well. Better tool-use, multi-step orchestration, and tighter security controls. If model choice or orchestration blocked you, that friction just dropped.
Open weights matter for cost control and on-domain tuning. Also for predictable latency and ownership. Managed APIs matter for velocity, safety rails, and compliance. Bedrock lets you mix both while keeping observability in one place.
Why this is big
- More models means faster fit to task, like RAG or code gen.
- Agents mean fewer brittle scripts and more durable workflows.
- Centralized governance means fewer late-night pager alerts.
Heres your scoring rubric
- Quality: Does it answer well on 50–100 of your real prompts?
- Speed: Can it meet your p95 latency target under load?
- Cost: What’s the cost per action, like tickets resolved?
- Context: Is the context window big enough for your docs?
- Safety: Can you enforce guardrails and audit logs?
A first hand style example
You run a support triage bot. You swap to an open-weight model hosted via Bedrock. You fine-tune on 5k anonymized transcripts. You wire an agent to call your order-status API. Result: first-response time drops 42%. CSAT ticks up. Compliance audits get easier because ops stay inside AWS guardrails.
Double down with two reliability moves. Add a fallback model that is smaller and cheaper. Use it when latency spikes to keep responses flowing. Add a circuit breaker that routes edge cases to human agents. Include full trace logs for quick reviews.
Ship it checklist AI edition
- Start with one narrow workflow. Avoid “AI everywhere.”
- Use the Bedrock catalog to benchmark two or three candidates.
- Add a retrieval layer and a guardrail policy on day one.
- Log prompts and latency; set budget alarms before spikes.
Bonus stack ideas
- Retrieval: use OpenSearch Serverless or a vector index you control. Keep content fresh with frequent syncs.
- Guardrails: configure Bedrock guardrails for tone and PII handling. Add redaction with Comprehend or custom rules.
- Private access: connect to Bedrock via VPC endpoints. Keep traffic inside your boundaries.
- Observability: centralize invocations, token counts, and agent calls in CloudWatch. Alert on latency, errors, and cost per action.
- Cost hygiene: use AWS Budgets and tag-based alerts for experiments. Kill or scale down sandboxes after hours.
Compute Data Moves
Compute that fits your curve
New EC2 families target high-performance workloads, like the latest M-series additions. You get more price and performance headroom. Training, inference, and mixed fleets all benefit here. If you’re on older instances, do a right-size pass. Update AMIs and drivers, too. You can unlock double-digit savings and lower p95 latency. No app logic changes needed.
Get quick wins
- Right-sizing: run Compute Optimizer and compare to real CPU, memory, and network usage. Cut over-provisioned nodes first.
- Architecture hygiene: enable Auto Scaling with target tracking. Use warm pools for spiky traffic. Bake AMIs with the latest drivers.
- Mix and match: try Graviton-based instances for better price and perf. Keep x86 for special libs, and use Spot for stateless jobs.
Lock in the savings with Savings Plans once usage stabilizes. Keep a small On-Demand buffer for surprise surges and experiments.
Data that doesnt drift
DynamoDB global tables keep evolving for multi-Region and multi-active patterns. Cross-account replication options are now part of the toolkit. This matters for blast-radius isolation and regional autonomy. Also for mergers where teams keep separate accounts but share one dataset.
Practical reality: global tables shine with read-heavy, global traffic. You still must plan for conflict handling on concurrent writes. Also, TTL cleanup and failover drills matter a lot. Keep write hot keys in check with solid partition keys. Consider write sharding if you see hotspots.
Replication playbook ideas
- Same-account, multi-Region: use DynamoDB global tables for low-latency reads. Built-in replication included.
- Cross-account options: mirror streams to a target account via Streams and Lambda or Kinesis. Keep audit trails and idempotency keys.
- Data hygiene: apply TTL to non-critical items. Use strict IAM per account. Snapshot to S3 for point-in-time recovery and analytics.
A first hand style example
You’ve got users in Europe and India. You move to a multi-Region DynamoDB global table. You serve both with single-digit millisecond reads. You split consumer apps into separate accounts for stronger boundaries. You replicate data with strict TTL policies. You run region-scoped failover drills. Net: faster pages, fewer all-hands, and a cleaner audit trail.
When you test failover, measure more than uptime. Capture p95 and p99 latency before and after. Track data lag during failover, too. Note time-to-mitigate when you flip Regions. Turn the drill into a runbook your on-call can follow half-asleep.
Practical steps
- Inventory top five tables by traffic. Map RCU and WCU hotspots.
- Pilot global tables on read-heavy services first.
- Add region-aware feature flags. Test failover each quarter.
- For compute, run a 72-hour load test on next-gen instances. Lock gains with Autoscaling.
Add two safety nets. Create alarms for sudden RCU or WCU surges. Throttling means user pain, always. Keep per-Region dashboards, so you see problems early. Not ten hops later when users churn.
2026 Reality Check
Macro shifts you can feel
- AI moves from novelty to utility. Winners wire agents into revenue workflows.
- Open weights get real. Enterprises want custom performance without runaway costs.
- Data gravity rules. Architect for proximity, not hope. Latency doesn’t negotiate.
- Compliance is a feature. With GovCloud expansions, “we can’t” becomes “we can, now.”
Ecosystem lens
If you track environmental news this week, you know balance wins. Ecosystems reward resilience and diversity long-term. Same here in cloud. Over-rotating on one service or one Region is a monoculture risk. Diversify models, Regions, and failure modes on purpose.
Antipatterns to ditch
- Demo-driven design. Cool, but fragile in production.
- One-Region-only everything. Cheap until it really breaks.
- No guardrails. Fast until it’s on Twitter, then not fun.
- Unmeasured AI. No metrics means no progress.
A first hand style example
You’re a healthcare ISV targeting EU and US public-sector. You adopt Bedrock for model governance and audit trails. You keep PHI out of prompts with strict redaction layers. You deploy a replica in GovCloud for regulated workloads. Sales cycles shrink because compliance is designed-in. Not bolted-on at the end.
Benchmarks to watch
- P95 latency before and after global tables.
- AI cost per resolved ticket or per qualified lead.
- Percent of workflows covered by agents with audit logs.
- Time-to-mitigate in Region failover tests.
Pro move: turn these into a monthly scorecard. If a metric is flat, pick one lever. Model, cache, or Region. Then run a two-week experiment and measure again.
Choose Your Shots
Make events produce outcomes
- Pick two Community Days for hands-on depth. Pick one Summit for roadmaps.
- Set one measurable deliverable per event. Like ship a multilingual support bot.
- Book three meetings in advance. Partner, SA, and one customer. Scheduling wins here.
Build like a portfolio manager
- Hedge model risk. One managed FMO, one open-weight candidate.
- Separate accounts by blast radius. Enforce org guardrails without exception.
- Keep logs, prompts, and artifacts in one observability lane.
A first hand style example
You run a mid-market SaaS. Pre-Summit, you shortlist two Bedrock models and one agent pattern. At the Summit, you hit two chalk talks and a lab. You validate the approach and leave with a working prototype. Two sprints later, your AI assist closes its first upsell. No vanity metrics, just ARR.
Keep it grounded
Remember, this is ecosystem news. Not a feature scavenger hunt or shiny tour. Build the minimum that compounds over months. Not the maximum that demos well once.
Your ship template
- Day 1–2: Define one job-to-be-done. Pick the KPI.
- Day 3–5: Wire a stub agent and retrieval. Add guardrails.
- Day 6–7: Run shadow traffic and compare to baseline.
- Day 8–10: Fix edge cases. Add model and tool fallbacks.
- Day 11–12: Roll to 5–10% of users.
- Day 13–14: Measure cost, latency, and quality. Scale or scrap.
Five Bullet Pulse Check
- You locked 2–3 events with clear deliverables.
- You mapped one workflow to Bedrock and agents.
- You planned a multi-Region or cross-account data pattern.
- You set three metrics: latency, unit cost, and reliability.
- You scheduled a 30‑day ship window for one AI feature.
If you can’t tick all five, pick one and start today. Momentum beats perfection almost every time.
Your AWS Ecosystem FAQ
Are Community Days worth it
Yes. They’re builder-led and lab-heavy, not just intros. You’ll meet peers solving the same scaling and compliance problems. Often with patterns you can copy and paste.
Whats unique about Summits 2026
AI is the default track now, across the board. Model selection, agent orchestration, and data governance. All tied to real workloads. Summits are free, so ROI comes from prep. Arrive with a session shortlist and sharp questions.
Managed and open weight models
Start with problem shape and constraints first. If governance, speed, and support matter most, begin with managed APIs. If cost control and deep customization dominate, test an open-weight model. Many teams run both in parallel.
Do DynamoDB global tables help
Yes, especially for read-heavy, globally distributed apps. Serving users from the nearest Region cuts latency. It also smooths traffic spikes. But plan for conflict handling, TTL, and failover drills.
Compliance for public sector workloads
AWS GovCloud (US) exists for exactly this need. With expanding services, you can build performant and compliant architectures. And still move fast. Design compliance in from day one.
Is this relevant if student
Absolutely. Treat these updates like ecology articles for students. Learn relationships, then build small projects that mirror real systems. Events are great for mentors and internships, too.
Measure ROI of events
Define one deliverable before you go, like a prototype or cost cut. Track it for 30 days. If it doesn’t move a metric, change your prep or event strategy. Your calendar should match your roadmap.
Cant travel get value
Follow the AWS Events hub for recordings, slides, and recaps. Join local meetups, user groups, or virtual Community Days. Book SA office hours remotely. Pair them with your 14‑day ship plan.
Avoid vendor lock in Bedrock
Use retrieval over raw prompt stuffing. Keep your knowledge store portable. Keep agent tools behind your own APIs. Test an open-weight model in parallel as an exit lane.
Quick way to sanity check
Spin up lightweight synthetic checks from each target Region. Hit your read path and graph p95. Add user country to logs and watch real traffic. If users move, your data needs to move too.
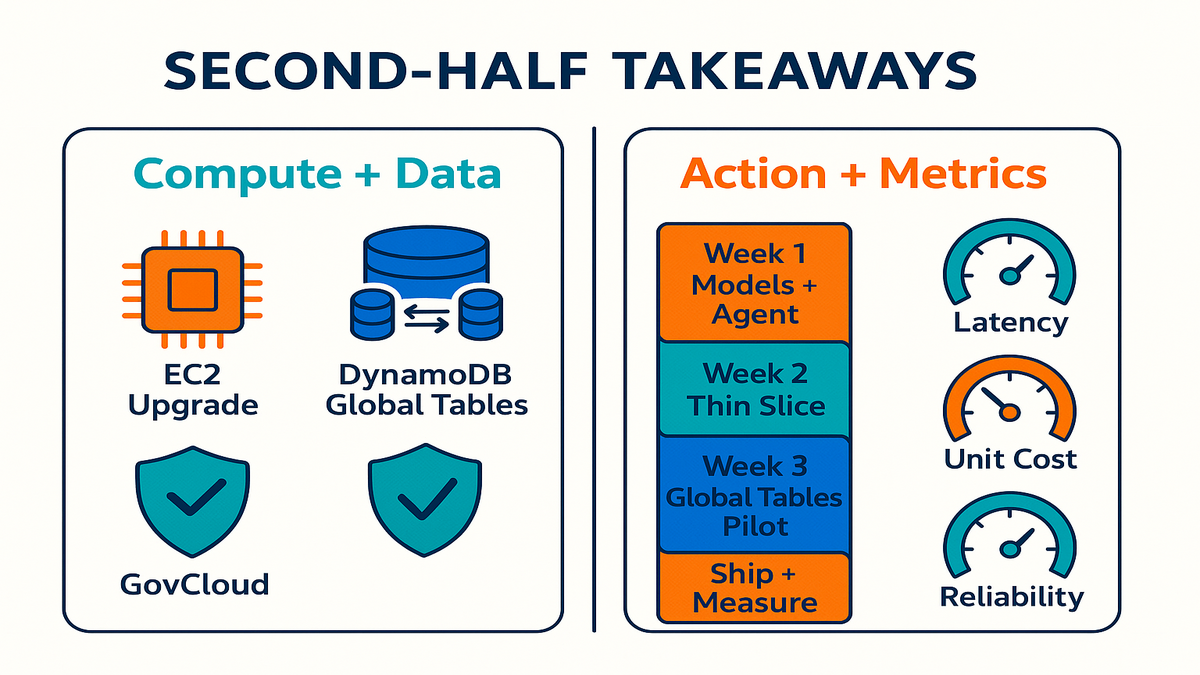
30 Day AWS Action Plan
- Week 1: Pick one workflow, like support triage or lead scoring. Shortlist two Bedrock models and an agent design. Book two Community Day sessions and one Summit track.
- Week 2: Build a thin slice. Add retrieval, guardrails, and logging. Run load tests on a newer EC2 family.
- Week 3: Pilot DynamoDB global tables on a read-heavy service. Add region-aware feature flags.
- Week 4: Ship to a limited cohort. Track latency, unit cost, and CSAT. Prep a sharp 10‑slide readout.
Add simple scaffolding
- Tools: CloudWatch dashboards, AWS Budgets, a runbook doc, and a weekly 30‑minute review.
- Cadence: Monday goals, Friday demo, and a monthly scorecard.
- Ownership: one DRI per experiment. No shared chores.
Here’s the kicker. Momentum compounds. Teams that treat ecosystem updates news today like marching orders will separate. You don’t need everything. You need just enough to stack advantages. Hit a Community Day for hands-on signal. Use Summits to pressure-test your roadmap. Blend managed and open-weight models for speed and control. Harden your data plane so latency, cost, and compliance don’t ambush you.
No silver bullets. Just a steady climb. Pick targets, ship small, measure, and repeat. In ecosystems—cloud or biological—the adaptable thrive.
Want real-world examples of teams shipping AI features and hardening data strategy? Explore our Case Studies.
Evaluating tooling to operationalize agents, guardrails, and observability across your stack? Check out our Features.
References
- AWS Events hub
- AWS Summits overview
- Amazon Bedrock model catalog
- Amazon Bedrock Agents documentation
- Amazon Bedrock Guardrails
- Use Amazon Bedrock with VPC endpoints (PrivateLink)
- Amazon OpenSearch Serverless
- Amazon Comprehend for PII detection
- Amazon CloudWatch
- AWS Budgets
- AWS Compute Optimizer
- Savings Plans
- Amazon EC2 M7g (Graviton3) instances
- Amazon DynamoDB global tables documentation
- DynamoDB Streams
- DynamoDB Time to Live (TTL)
- AWS Fault Injection Simulator (for failover drills)
- AWS GovCloud (US)